# Carregue os pacotes ou instale-os no caso de ainda não ter.
library(tidyverse)
library(psych)
library(GPArotation)Análise Fatorial Exploratória (EFA)
Conceitos e práticas de Análise Fatorial Exploratória (EFA) usando R
Modelos
O que é a EFA
A Análise Fatorial Exploratória (EFA) é uma técnica estatística multivariada usada para identificar a estrutura subjacente (fatores latentes) em um conjunto de variáveis observadas. Ela busca agrupar variáveis correlacionadas entre si em fatores comuns, revelando padrões ocultos nos dados.
É chamada de “exploratória” porque não parte de uma hipótese prévia sobre o número ou a natureza dos fatores, ao contrário da Análise Fatorial Confirmatória (CFA), que testa modelos específicos.
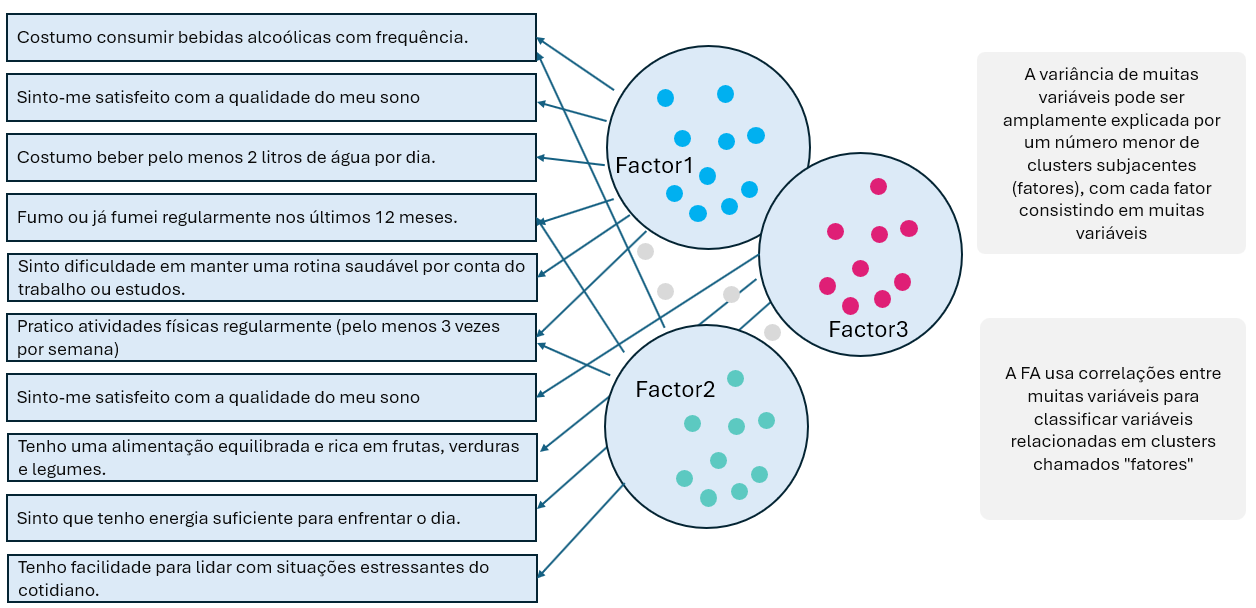
Qual o objetivo?
O principal objetivo da EFA é reduzir a dimensionalidade dos dados e descobrir estruturas latentes que explicam as correlações entre variáveis. Isso permite:
- Identificar agrupamentos naturais de variáveis.
- Compreender melhor os construtos teóricos por trás dos dados.
- Preparar modelos mais simples e interpretáveis.
- Apoiar o desenvolvimento de escalas e instrumentos de medida (como questionários).
De onde vem?
Ela surgiu no campo da psicometria e da psicologia, especialmente para entender traços de personalidade e habilidades cognitivas. Foi desenvolvida como uma resposta à necessidade de compreender fenômenos complexos que não podiam ser observados diretamente, mas inferidos a partir de múltiplas variáveis.
Ela se baseia em conceitos de correlação, covariância e álgebra linear, especialmente decomposição de matrizes.
Como fazer?
Aqui está um passo a passo prático para realizar uma EFA em R:
Preparar os dados verificando se há dados faltantes, certifique-se de que as variáveis são numéricas e correlacionáveis.
Verificar a adequação dos dados usando teste de Kaiser-Meyer-Olkin (KMO) e ou teste de esfericidade de Bartlett.
Escolher o número de fatores usando scree plot (gráfico de sedimentação), critério de Kaiser (autovalores > 1), e análise paralela.
Executar a EFA usando a função
factanal()ou pacotes comopsych(fa()), escolher o método de extração (ex: máxima verossimilhança, componentes principais) e escolher o tipo de rotação (ex: varimax, oblimin).Interpretar os resultados analisando as cargas fatoriais, verificando comunalidades e variância explicada e validar a consistência dos fatores.
Refinar o modelo eliminando variáveis com baixa carga ou comunalidade e reexecutando a análise se necessário.
Para praticar, iremos usar três exemplos sendo o primeiro com dados contínuos o segundo com com dados categóricos dicotômicos, e terceiro com dados mistos(categóricos dicotômicos e ordinais e numéricos).
Caso1: Comportamento de consumo com variáveis contínuas
Imagine que estou conduzindo uma análise fatorial em um questionário com 12 variáveis que representam respostas sobre comportamento de consumo.
Vamos instalar ou chamar os pacotes necessários.
Vamos criar um conjunto de dados com 12 variáveis que representam respostas a um questionário sobre comportamento de consumo, agrupadas em 3 fatores latentes.
Quando simulamos variáveis contínuas para representar respostas de um questionário, estamos aproximando o comportamento de escalas de Likert que foram normalizadas ou tratadas como contínuas.
As escalas de Likert são ordinais, geralmente com 5 ou 7 pontos, como:
1 = Discordo totalmente, 2 = Discordo, 3 = Neutro, 4 = Concordo, 5 = Concordo totalmente
Apesar de serem categorias ordenadas, na prática estatística (especialmente em psicometria e ciências sociais), elas são frequentemente tratadas como variáveis contínuas, principalmente quando há muitos itens (variáveis), a escala tem mais de 4 pontos e os dados são usados em modelos paramétricos como EFA, regressão, etc.
Na simulação abaixo, as variáveis foram geradas como contínuas com ruído, o que simula o comportamento de respostas em Likert. Isso equivale a dizer que os dados passaram por uma transformação ou suavização como por exemplo padronização (z-score), conversão para escala contínua (ex: média de itens), tratamento como intervalares para fins de modelagem.
#| label: case1_data
#| warning: false
#| message: false
# este comando permite replicarmos os dados randomicos
set.seed(123)
# Simulando 300 pontos de dados com 3 fatores latentes
n <- 300
fator1 <- rnorm(n)
fator2 <- rnorm(n)
fator3 <- rnorm(n)
dados <- tibble(
consumo_online1 = fator1 + rnorm(n, 0, 0.5),
consumo_online2 = fator1 + rnorm(n, 0, 0.5),
consumo_online3 = fator1 + rnorm(n, 0, 0.5),
fidelidade_marca1 = fator2 + rnorm(n, 0, 0.5),
fidelidade_marca2 = fator2 + rnorm(n, 0, 0.5),
fidelidade_marca3 = fator2 + rnorm(n, 0, 0.5),
preocupação_preço1 = fator3 + rnorm(n, 0, 0.5),
preocupação_preço2 = fator3 + rnorm(n, 0, 0.5),
preocupação_preço3 = fator3 + rnorm(n, 0, 0.5),
misc1 = rnorm(n),
misc2 = rnorm(n),
misc3 = rnorm(n)
)Em seguida, faremos a verificação e adequação dos dados usando funções como KMO e Teste de esfericidade de Bartlett.
# Teste KMO
KMO_result <- KMO(cor(dados))
print(KMO_result)Kaiser-Meyer-Olkin factor adequacy
Call: KMO(r = cor(dados))
Overall MSA = 0.75
MSA for each item =
consumo_online1 consumo_online2 consumo_online3 fidelidade_marca1
0.71 0.76 0.77 0.77
fidelidade_marca2 fidelidade_marca3 preocupação_preço1 preocupação_preço2
0.76 0.74 0.75 0.79
preocupação_preço3 misc1 misc2 misc3
0.73 0.42 0.69 0.49 # Teste de esfericidade de Bartlett
cortest.bartlett(cor(dados), n = n)$chisq
[1] 2002.223
$p.value
[1] 0
$df
[1] 66Em seguinda faremos a escolha do número de fatores. O gráfico Scree Plot nos ajudará a visualizar o número ideal de fatores com base nos autovalores.
# Scree plot
fa.parallel(dados, fa = "fa", n.obs = n)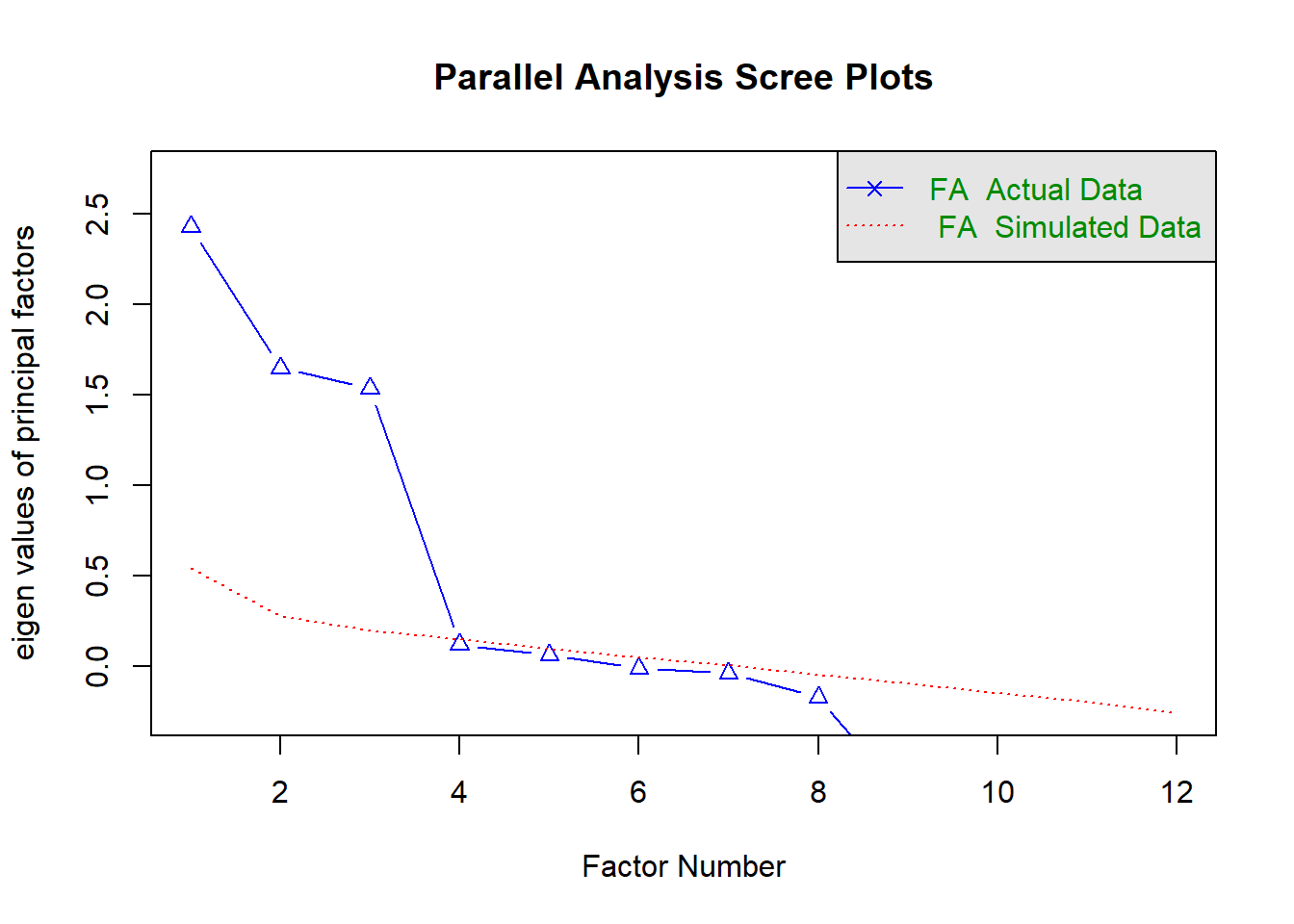
Parallel analysis suggests that the number of factors = 3 and the number of components = NA Vamos executar da analise fatorial exploratória.
# Análise fatorial com 3 fatores e rotação varimax
efa_result <- fa(dados, nfactors = 3, rotate = "varimax", fm = "ml")
print(efa_result)Factor Analysis using method = ml
Call: fa(r = dados, nfactors = 3, rotate = "varimax", fm = "ml")
Standardized loadings (pattern matrix) based upon correlation matrix
ML2 ML1 ML3 h2 u2 com
consumo_online1 0.03 -0.01 0.91 0.8360 0.16 1.0
consumo_online2 -0.03 0.01 0.87 0.7552 0.24 1.0
consumo_online3 -0.03 0.00 0.87 0.7518 0.25 1.0
fidelidade_marca1 0.89 -0.06 -0.02 0.7881 0.21 1.0
fidelidade_marca2 0.89 -0.04 -0.04 0.7952 0.20 1.0
fidelidade_marca3 0.91 -0.06 -0.03 0.8257 0.17 1.0
preocupação_preço1 0.00 0.90 -0.02 0.8031 0.20 1.0
preocupação_preço2 0.03 0.87 -0.03 0.7577 0.24 1.0
preocupação_preço3 0.04 0.92 0.00 0.8402 0.16 1.0
misc1 0.04 -0.08 -0.03 0.0081 0.99 1.7
misc2 -0.07 0.01 0.08 0.0110 0.99 2.1
misc3 -0.07 -0.04 -0.07 0.0107 0.99 2.5
ML2 ML1 ML3
SS loadings 2.42 2.41 2.35
Proportion Var 0.20 0.20 0.20
Cumulative Var 0.20 0.40 0.60
Proportion Explained 0.34 0.34 0.33
Cumulative Proportion 0.34 0.67 1.00
Mean item complexity = 1.3
Test of the hypothesis that 3 factors are sufficient.
df null model = 66 with the objective function = 6.81 with Chi Square = 2002.22
df of the model are 33 and the objective function was 0.1
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 300 with the empirical chi square 18.99 with prob < 0.98
The total n.obs was 300 with Likelihood Chi Square = 29.2 with prob < 0.66
Tucker Lewis Index of factoring reliability = 1.004
RMSEA index = 0 and the 90 % confidence intervals are 0 0.035
BIC = -159.03
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
ML2 ML1 ML3
Correlation of (regression) scores with factors 0.96 0.96 0.96
Multiple R square of scores with factors 0.92 0.93 0.92
Minimum correlation of possible factor scores 0.85 0.85 0.84Vamos fazer a interpretação dos resultados
# Cargas fatoriais
efa_result$loadings
Loadings:
ML2 ML1 ML3
consumo_online1 0.914
consumo_online2 0.868
consumo_online3 0.866
fidelidade_marca1 0.886
fidelidade_marca2 0.890
fidelidade_marca3 0.906
preocupação_preço1 0.896
preocupação_preço2 0.869
preocupação_preço3 0.916
misc1
misc2
misc3
ML2 ML1 ML3
SS loadings 2.416 2.412 2.355
Proportion Var 0.201 0.201 0.196
Cumulative Var 0.201 0.402 0.599# Comunalidades
efa_result$communality consumo_online1 consumo_online2 consumo_online3 fidelidade_marca1
0.836026811 0.755214413 0.751755055 0.788072368
fidelidade_marca2 fidelidade_marca3 preocupação_preço1 preocupação_preço2
0.795239486 0.825689239 0.803057069 0.757746899
preocupação_preço3 misc1 misc2 misc3
0.840216665 0.008060549 0.010976924 0.010747541 # Variância explicada
efa_result$Vaccounted ML2 ML1 ML3
SS loadings 2.4158011 2.4123976 2.3546043
Proportion Var 0.2013168 0.2010331 0.1962170
Cumulative Var 0.2013168 0.4023499 0.5985669
Proportion Explained 0.3363313 0.3358574 0.3278113
Cumulative Proportion 0.3363313 0.6721887 1.0000000
Clique aqui para exibir detalhes sobre a interpretação dos resultados
Caso2 - Sintomas de saúde com variáveis dicotômicas
Imagine que estou conduzindo uma análise fatorial para investigar uma possível estrutura latente para 10 sintomas definidos apenas por variáveis dicotômicas (0 = ausente, 1 = presente). Preciso realizar uma análise fatorial exploratória apenas com variáveis categóricas para isso preciso saber qual a melhor abordagem e matriz de correlação utilizar.
Quando lidamos com variáveis dicotômicas (0 = ausente, 1 = presente) em uma análise fatorial exploratória, precisamos adaptar a abordagem tradicional, pois a matriz de correlação padrão (Pearson) não é apropriada para variáveis categóricas.
Para casos como este, a correlação tetra-córica é mais adequada. Ela é ideal para variáveis dicotômicas que representam uma versão categorizada de uma variável contínua subjacente, pois estima a correlação entre essas variáveis como se fossem contínuas e normalmente distribuídas.
Vamos carregar os pacotes
library(tidyverse)
library(psych)
library(polycor)Vamos gerar os dados para a simulação.
set.seed(123)
n <- 300
dados_binarios <- tibble(
febre = rbinom(n, 1, 0.6),
tosse = rbinom(n, 1, 0.5),
fadiga = rbinom(n, 1, 0.4),
dor_cabeca = rbinom(n, 1, 0.5),
falta_ar = rbinom(n, 1, 0.3),
dor_muscular = rbinom(n, 1, 0.4),
perda_olfato = rbinom(n, 1, 0.2),
perda_paladar = rbinom(n, 1, 0.2),
congestao = rbinom(n, 1, 0.3),
nauseas = rbinom(n, 1, 0.25)
)Vamos gerar a matriz de correlação.
# Matriz de correlação tetra-córica
matriz_tetra <- tetrachoric(dados_binarios)$rhofa.parallel(matriz_tetra, n.obs = n, fa = "fa")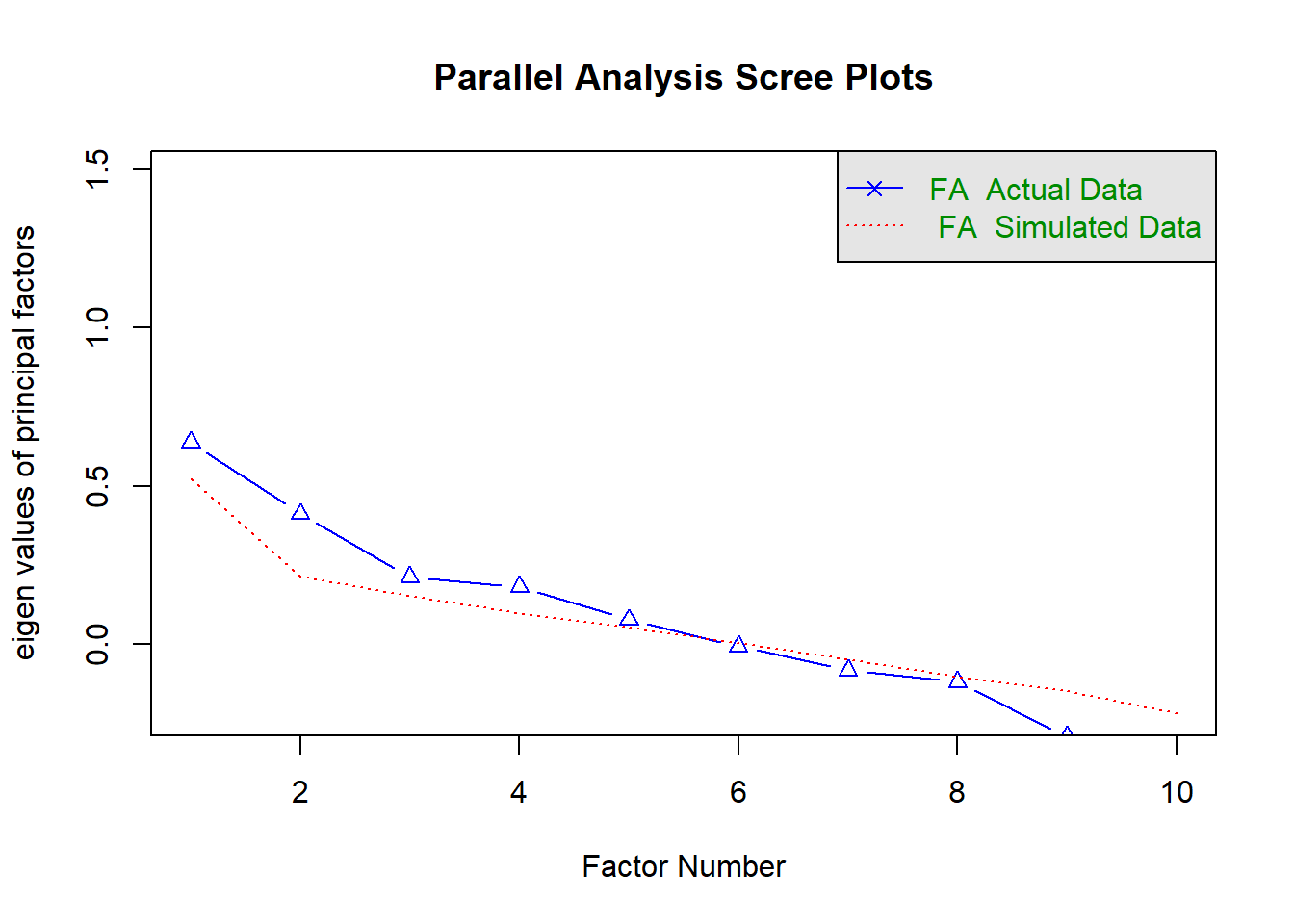
Parallel analysis suggests that the number of factors = 5 and the number of components = NA efa_binaria <- fa(matriz_tetra, nfactors = 2, rotate = "varimax", fm = "ml")
efa_binariaFactor Analysis using method = ml
Call: fa(r = matriz_tetra, nfactors = 2, rotate = "varimax", fm = "ml")
Standardized loadings (pattern matrix) based upon correlation matrix
ML1 ML2 h2 u2 com
febre 1.00 -0.05 0.9950 0.005 1.0
tosse 0.16 0.27 0.0980 0.902 1.6
fadiga -0.05 0.10 0.0133 0.987 1.4
dor_cabeca 0.05 0.26 0.0705 0.929 1.1
falta_ar -0.16 0.35 0.1442 0.856 1.4
dor_muscular -0.03 0.32 0.1068 0.893 1.0
perda_olfato 0.07 0.51 0.2639 0.736 1.0
perda_paladar -0.17 0.08 0.0352 0.965 1.4
congestao 0.18 0.06 0.0369 0.963 1.2
nauseas -0.10 0.00 0.0091 0.991 1.0
ML1 ML2
SS loadings 1.12 0.65
Proportion Var 0.11 0.06
Cumulative Var 0.11 0.18
Proportion Explained 0.63 0.37
Cumulative Proportion 0.63 1.00
Mean item complexity = 1.2
Test of the hypothesis that 2 factors are sufficient.
df null model = 45 with the objective function = 0.42
df of the model are 26 and the objective function was 0.16
The root mean square of the residuals (RMSR) is 0.05
The df corrected root mean square of the residuals is 0.07
Fit based upon off diagonal values = 0.68
Measures of factor score adequacy
ML1 ML2
Correlation of (regression) scores with factors 1.00 0.66
Multiple R square of scores with factors 0.99 0.44
Minimum correlation of possible factor scores 0.99 -0.12# Cargas fatoriais
efa_binaria$loadings
Loadings:
ML1 ML2
febre 0.996
tosse 0.156 0.272
fadiga 0.104
dor_cabeca 0.262
falta_ar -0.155 0.347
dor_muscular 0.325
perda_olfato 0.509
perda_paladar -0.170
congestao 0.181
nauseas
ML1 ML2
SS loadings 1.123 0.650
Proportion Var 0.112 0.065
Cumulative Var 0.112 0.177# Variância explicada
efa_binaria$Vaccounted ML1 ML2
SS loadings 1.1228582 0.64994134
Proportion Var 0.1122858 0.06499413
Cumulative Var 0.1122858 0.17727995
Proportion Explained 0.6333814 0.36661863
Cumulative Proportion 0.6333814 1.00000000
Clique aqui para exibir detalhes sobre a interpretação dos resultados
Caso3 - Sintomas de saúde com variáveis mistas
Quando temos variáveis mistas em um questionário (algumas dicotômicas e outras em escala de Likert), a escolha da abordagem para a análise fatorial exploratória precisa considerar a natureza dos dados para garantir resultados válidos.
A correlação policórica/tetra-córica pode ser mais adequada para estes casos sendo que:
- As variáveis dicotômicas (0/1) devem ser tratadas com correlação tetra-córica.
- As variáveis ordinais (Likert) devem ser tratadas com correlação policórica.
- Tratar todas como contínuas (usando correlação de Pearson) pode distorcer os resultados, especialmente se houver muitas variáveis dicotômicas ou escalas curtas (ex: Likert de 3 ou 5 pontos).
O pacote polycor oferece a função hetcor() que calcula uma matriz de correlação heterogênea, combinando pearson para variáveis contínuas, policórica para variáveis ordinais, tetra-córica para variáveis dicotômicas.
library(psych)
# Escolher número de fatores (opcional)
fa.parallel(matriz_het, n.obs = 300, fa = "fa")
# Executar EFA
efa_mista <- fa(matriz_het, nfactors = 2, rotate = "varimax", fm = "ml")
print(efa_mista)
Clique aqui para exibir detalhes sobre a interpretação dos resultados
Pra onde vai?
A análise fatorial exploratória serve como base para modelos mais avançados, como a Análise Fatorial Confirmatória (CFA) e Modelagem de Equações Estruturais (SEM) e é amplamente utilizada em diferentes áreas como:
- Psicologia e educação: desenvolvimento de testes e escalas.
- Marketing: segmentação de consumidores com base em comportamentos.
- Saúde: identificação de padrões em sintomas ou respostas a tratamentos.
- Ciências sociais: estudo de atitudes, valores e crenças.
Qual resultado?
Após realizarmos a análise fatorial exploratória
- Um conjunto de fatores latentes que explicam a estrutura dos dados.
- Redução da complexidade do modelo.
- Melhor compreensão dos constructos teóricos.
- Um modelo mais parcimonioso e interpretável.
Esses resultados ajudam na tomada de decisão, no desenvolvimento de instrumentos de medida e na validação de teorias.