Packages
# packages ----------------------------------------------------------------
library(tidyverse)
library(tidymodels)
library(tidyquant)
library(quantmod) #freadR
library(scales)Funções úteis split de dados e resample que serão usados na validação e ajuste de modelos
Vídeo tema para este post em Amostra e reamostragem com Rsample
bias e variancePacotes
Para reproduzir os códigos abaixo serão necessários os pacotes tidyverse , tidymodels,tidyquant e quantmod
Dados
Foram usados dados do conjunto ames housing,DGS10eEWZcomo exemplo. Todos eles são possíveis acessar através dos códigos descritos abaixo.
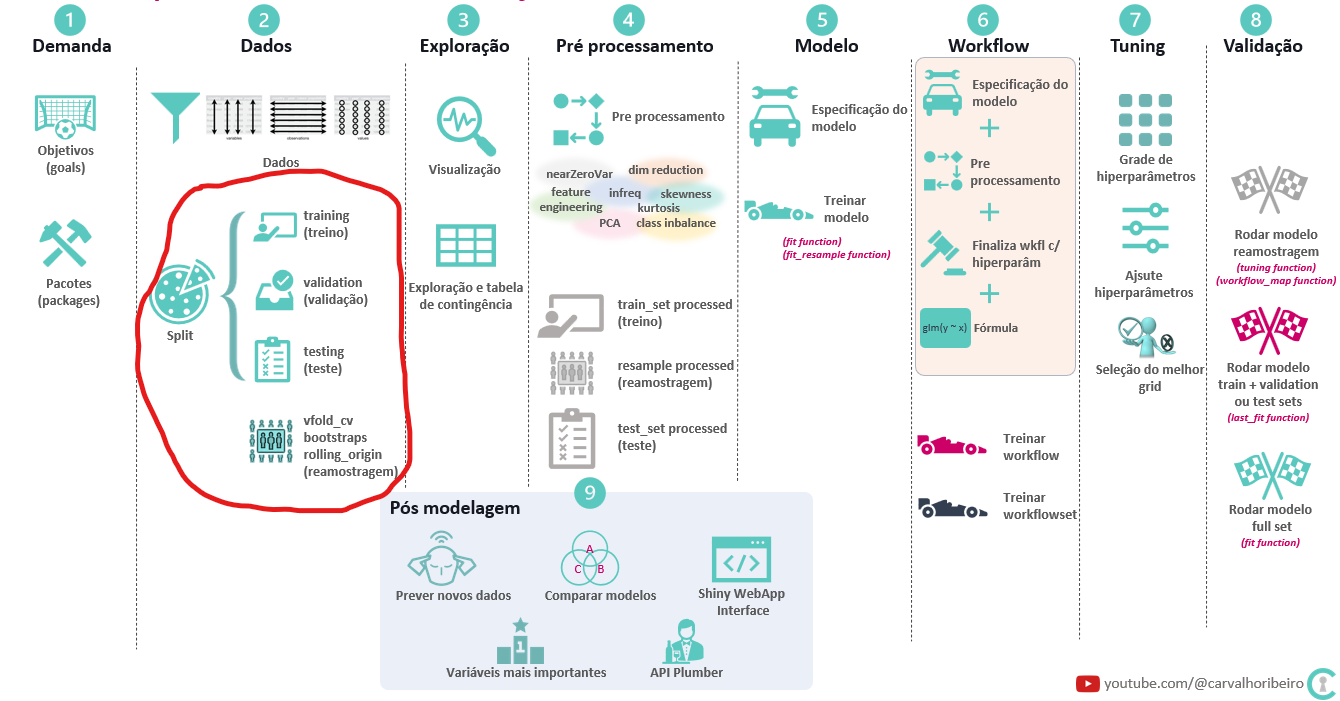
Etapa do projeto
Código reproduzível
Packages
# packages ----------------------------------------------------------------
library(tidyverse)
library(tidymodels)
library(tidyquant)
library(quantmod) #freadR
library(scales)Models
# data --------------------------------------------------------------------
#ames housing case
data(ames)
data_ames <-
ames %>%
mutate(Sale_Price = log10(Sale_Price))
# simple split ------------------------------------------------------------
split_ames <- initial_split(ames, strata = Sale_Price)
train_ames <- training(split_ames)
test_ames <- testing(split_ames)
# validation split --------------------------------------------------------
split_val_ames <- initial_validation_split(ames, strata = Sale_Price)
train_val_ames <- training(split_val_ames)
val_ames <- validation(split_val_ames)
test_val_ames <- testing(split_val_ames)
# time split --------------------------------------------------------------
data_10y <- tq_get("DGS10", get = "economic.data")
data_10y %>%
ggplot(aes(x = date, y = price))+
geom_line()
split_10y <- initial_time_split(data_10y)
train_10y <- training(split_10y)
test_10y <- testing(split_10y)
train_10y %>% tail()
test_10y %>% head()
c(max(train_10y$date), min(test_10y$date))
# time split lag ----------------------------------------------------------
split_10y_lag <- initial_time_split(data_10y, lag = 20)
train_10y_lag <- training(split_10y_lag)
test_10y_lag <- testing(split_10y_lag)
train_10y_lag %>% tail()
test_10y_lag %>% head()
c(max(train_10y_lag$date), min(test_10y_lag$date))
# resample simple ---------------------------------------------------------
resample_ames <- vfold_cv(train_ames, strata = Sale_Price, v=10)
resample_ames
# resample time -----------------------------------------------------------
resample_10y <- rolling_origin(train_10y_lag,
initial = 50,
assess = 10)
# resample group ----------------------------------------------------------
set.seed(1353)
car_split <- group_initial_split(mtcars, cyl)
train_data <- training(car_split)
test_data <- testing(car_split)
# resample time group -----------------------------------------------------
getSymbols("EWZ")
chartSeries(EWZ)
#xts o df
ibov_usd <- fortify.zoo(EWZ) %>% janitor::clean_names()
#reamostragem por grupo
resample_ibov_usd <-
ibov_usd %>%
mutate(ym = as.POSIXlt(index)$year + 1900) %>%
nest(data = c(-ym)) %>%
rolling_origin(cumulative = FALSE)
analysis(resample_ibov_usd$splits[[2]])
assessment(resample_ibov_usd$splits[[2]]) Aperfeiçoamento das técnicas separação entre dados de treino, teste, validação e reamostragem mais adequados para cada caso.
Facilitar o trabalho e melhorar o processo para o grupo responsável pelas próximas etapas no projeto.
Permitir a aplicação prática dos resultados dos modelos através da melhoria de acuracidade e poder preditivo gerando benefícios para os usuários do modelo e para a sociedade.