Conceitos e práticas de structural equation modeling SEM usando R
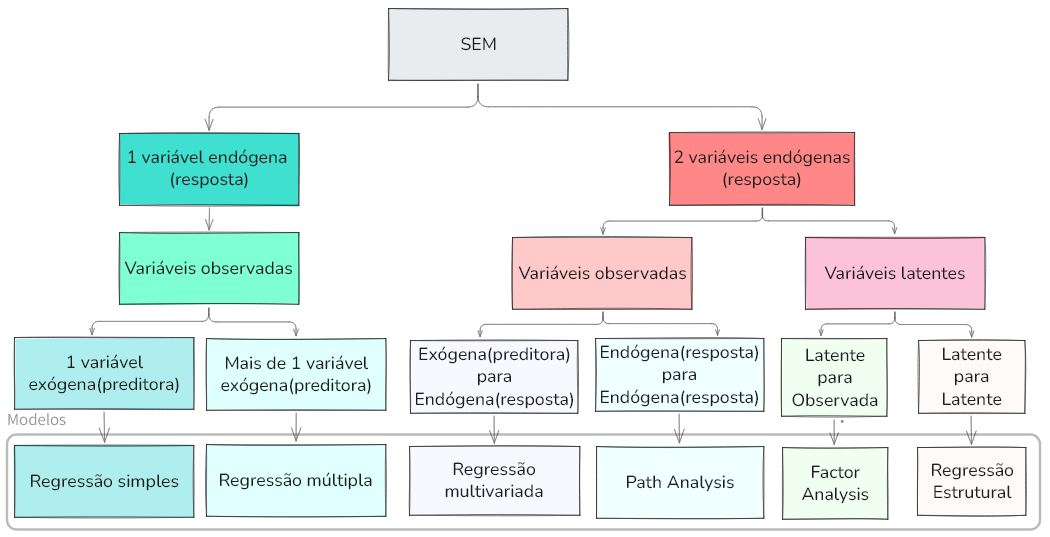
Modelos
Author
Marcelo Carvalho dos Anjos
Published
August 22, 2025
O que é a SEM
No contexto da manufatura e melhoria de processos o SEM é uma ferramenta estatística que ajuda a entender como diferents fatores dentro de um processo estão conectados permitindo analisar várias causas e efeitos ao mesmo tempo, mesmo quando alguns desses fatores não são diretamente medidos(e.g. clima organizacional, engajamento dos operadores, motivação etc).
É uma abordagem estatística poderosa e flexível que permite investigar relações complexas entre variáveis observadas (dados coletados) e variáveis latentes (conceitos não diretamente mensuráveis, como inteligência ou satisfação), mas que são inferidas a partir de indicadores. Ela combina elementos de análise fatorial e regressão múltipla em um único modelo.
Diferente dos modelos tradicionais de regressão que analisam uma única equação por vez, o SEM trabalhar com múltiplas equações simultaneamene. O SEM incorpora várias técnicas estatísticas como modelos de regressão linear, modelos de análise fatorial, path analysis, modelos com variáveis latentes, modelos de medição e ponderação e modelos hierárquicos ou multigrupo
Modelos disponíveis no pacote lavaan para R
Clique aqui para expandir detalhes sobre o que são variáveis latentes e variáveis observadas
Variáveis observadas: Ajudam a controlar e monitorar o processo. São coisas que conseguimos medir diretamente no chão da fábrica(e.g. temperatura de uma maquina, tempo de produção de uma peça, número de peças com defeito, peso de um produto, horas de treinamento recebidos). Estas variáveis vêm de sensores, relatórios ou medições feitas por pessoas. Elas são vistas e registradas.
Variáveis latentes: Ajudam a entender o que está por trás dos resultados e melhorar o sistema de forma mais profunda. São coisas que não conseguimos medir diretamente, mas que influenciam o processo. É necessário usar outras variáveis para estimar ou representá-las(e.g. motivação dos operadores, qualidade do ambiente de trabalho, engajamento com segurança, cultura de melhoria contínua, satisfação com treinamento). Não há um sensor que mede a motivação por exemplo, mas pode-se utilizar de perguntas de uma pesquisa ou observar o comportamentos para representar esse conceito.
PS. Há conteúdos no Youtube de excelente qualidade que ajudam a compreender melhor esses modelos e suas aplicações como por exemplo, o do professor Prof. Diogenes S. BIDO (2021)
Qual o objetivo?
Identificar relações ocultas entre variáveis de processo, qualidade, produtividade e comportamento humano.
Melhorar decisões com base em dados, não só em intuição.
Validar hipóteses sobre o que realmente afeta o desempenho(e.g. em uma linha de produção, satisfação dos consumidores).
Modelar relações causais entre variáveis.
Testar teorias que envolvem múltiplas dependências simultâneas.
Validar construtos teóricos por meio de dados empíricos.
Avaliar a qualidade de modelos estatísticos complexos.
De onde vem?
Na área acadêmica, o SEM surgiu para estudar fenômenos complexos como comportamento humano, educação e psicologia onde foi desenvolvido a partir da evolução da análise fatorial e da path analysis (análise de caminhos), ganhando força nas ciências sociais, psicologia, marketing e educação. Foi desenvolvido sobre a estrutura do LISREL Joreskög (2004)
A necessidade surgiu da limitação de métodos estatísticos tradicionais (como regressão simples ou múltipla) que não conseguiam capturar relações simultâneas entre múltiplas variáveis, trabalhar com variáveis latentes (não diretamente mensuráveis) e testar modelos teóricos complexos com múltiplas etapas e dependências.
Na industria onde há sistemas igualmente complexos como uma fábrica com centenas de variáveis interagindo. Ela surge como ferramenta complementar a métodos tradicionais(e.g. gráficos de controle, regressão simples etc) os quais podem não conseguir capturar todas as complexidades existentes no processo. O SEM entra como uma solução para modelar sistemas industriais de forma mais completa.
Por que usaríamos um SEM em vez de um modelo de regressão linear?
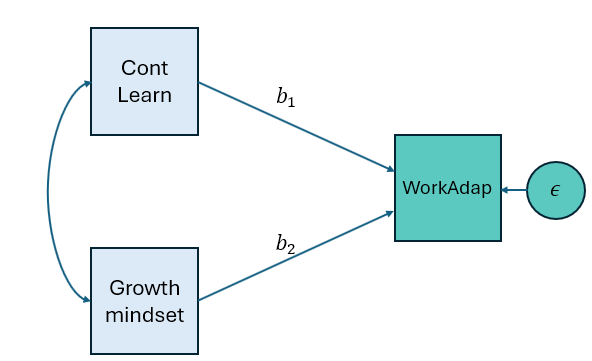
Para exemplificar melhor, imagine que estamos estudando a adaptabilidade da força de trabalho em um cenário de rápida mudança tecnológica e queremos saber quais fatores preveem essa adaptabilidade.
Exemplo de modelo de regressão linear
Digamos que temos dois preditores de interesse Habilidade de Aprendizagem Contínua(Cont Learn), e Mentalidade de Crescimento(Growth mindset) dos trabalhadores as quais afetam a Adaptabilidade da Força de Trabalho(WorkAdap). Nessa situação, teremos o problema do erro de medida, pois não sabemos se nossas estimativas serão viesadas para baixo (como no caso de apenas um único preditor) ou até para cima em algumas situações. Por exemplo, se nossa medida de “Habilidade de Aprendizagem Contínua” for mal medida e tiver baixa confiabilidade, não estamos controlando adequadamente o efeito dela ao avaliar o efeito da “Mentalidade de Crescimento”. Isso poderia levar a uma superestimação do efeito de “Mentalidade de Crescimento” (b2). Basicamente, quando tentamos ajustar esses tipos de modelos em um framework de regressão padrão, nossas estimativas de efeito são viesadas devido à falta de confiabilidade, e quando há erro de medida em nossas variáveis de resultado, ele vai para o termo de erro do modelo. Qualquer erro ali, sendo aleatório, não pode ser previsto pelos preditores. Isso significa que, embora nossas estimativas de parâmetro não sejam viesadas, o que é viesado é nosso R². O R² do modelo tende a ser muito pequeno, nossos erros padrão para essas estimativas são inflacionados, então perdemos poder para detectar esses efeitos.
E no modelo SEM como ficaria?
Exemplo de flexibilidade de modelos SEM
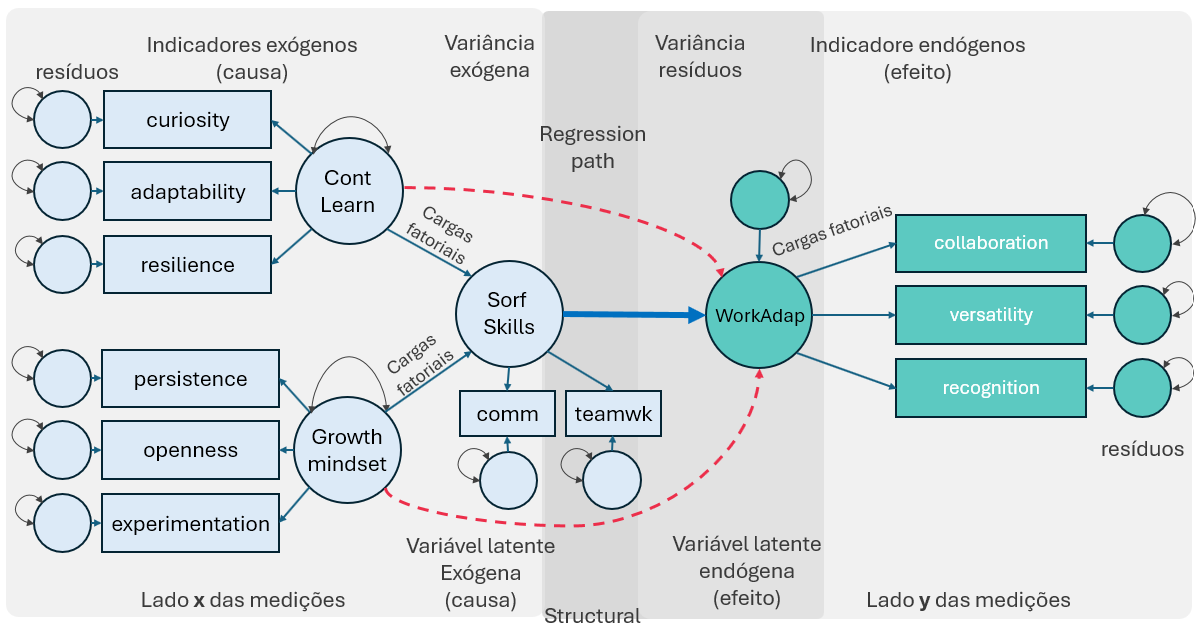
A primeira vantagem do modelo de equações estruturais é que ele nos permite superar esse problema do erro de medida. A forma como abordamos isso no SEM é obtendo múltiplas medidas indicadoras para cada uma das variáveis de interesse.
Se estamos interessados na Habilidade de Aprendizagem Contínua Cont Learn, o que realmente nos interessa é o construto latente subjacente. Não podemos medir diretamente a “Habilidade de Aprendizagem Contínua” com perfeita confiabilidade, mas podemos obter múltiplas medidas indiretas(e.g. curiosity,adaptability,`resilience``) através de um questionário de 3 itens para avaliar a autopercepção dos trabalhadores sobre sua capacidade de aprender novas habilidades.
Esses 3 itens medem a “Habilidade de Aprendizagem Contínua” e a variância comum é então incorporada ao fator latente recem criado que fornece uma medida livre de erro nesa variável.
Podemos ter também, uma medida de Mentalidade de Crescimento Growth mindset, obtida por meio de 3 indicadores(e.g. persistence,openness e experimentation) onde pedimos aos trabalhadores que descrevam como eles reagiriam a desafios ou feedback, avaliando sua resiliência e perspectiva de melhoria.
Os dois construtos latentes recem criados, estarão correlacionados e esperamos que cada um deles preveja a Adaptabilidade da Força de Trabalho WorkAdap.
Idealmente, também mediríamos a “Adaptabilidade da Força de Trabalho” com múltiplas variáveis indicadoras(e.g. collaboration,versatility e recognition) onde poderíamos ter medidas de networl, capacidade de se adaptar a novas tecnologias e sentimento sobre a valorização da empresa sobre suas contribuições.
Estimativas não viesadas: é quando obtemos nossas estimativas de b1 e b2, as estimativas não são contaminadas por erro de medida. Elas são estimativas não viesadas dos efeitos verdadeiros de “Habilidade de Aprendizagem Contínua” e “Mentalidade de Crescimento” sobre “Adaptabilidade da Força de Trabalho” na população.
Teste da estrutura do modelo: é a capacidade do modelo de nos fornecer testes para avaliar se nossos modelos realmente reproduzem as associações observadas entre as variáveis(os indicadores nos retângulos). O modelo, está assumindo que as relações entre essas variáveis indicadoras são explicadas pelas associações entre essas variáveis latentes(e.g as três medidas de “Adaptabilidade” estão associadas às três medidas de “Habilidade de Aprendizagem Contínua” através deste efeito aqui (b1) e como essas medidas se relacionam com seus respectivos fatores latentes. Da mesma forma, as três medidas de “Adaptabilidade” estão relacionadas às três medidas de “Mentalidade de Crescimento” através do fator latente.
Podemos avaliar se os padrões de associação implícitos entre essas variáveis indicadoras observadas são consistentes com as associações reais que observamos em nossos dados empíricos, para determinar se este modelo é um modelo razoável para nossos dados ou não. Assim, obtemos testes de ajuste do modelo que podemos usar para avaliar a qualidade do nosso modelo para os dados.
Modelos Teóricos Complexos: significa que podemos especificar estruturas de modelos mais complexas do que podemos fazer em um de regressão tradicional. Por exemplo, Bonvillian and Sarma (2021) sugerem que o desenvolvimento de certas soft skills podem mediar a relação entre a capacidade individual e a adaptabilidade no local de trabalho.
Poderíamos dizer que o “soft skills” é medido por avaliações de pares no local de trabalho comm e autoavaliações de colaboração teamwork.
Argumentamos que a “Habilidade de Aprendizagem Contínua” e a “Mentalidade de Crescimento” que são as variáveis latentes exógenas preveem níveis mais altos de “soft skills”, e o “soft skills”, por sua vez, prevê níveis mais altos de “Adaptabilidade da Força de Trabalho”.
Podemos especificar modelos como este, que incorporam uma teoria mais complexa que fala sobre uma cadeia causal, onde esses fatores “Habilidade de Aprendizagem Contínua” e “Mentalidade de Crescimento” afetam a “Adaptabilidade da Força de Trabalho”, mas através de sua influência no “soft skills”, que é, em última análise, a causa mais próxima dessa diferença na “Adaptabilidade”.
Podemos testar se esse modelo é consistente com as associações que vemos nos dados observados. E podemos comparar o ajuste desse modelo a modelos alternativos.
Outro exemplo é que poderíamos especular que talvez todo o efeito da “Habilidade de Aprendizagem Contínua” e “Mentalidade de Crescimento” sobre a “Adaptabilidade da Força de Trabalho” passa pelo “soft skills”(linha azul na figua). Mas talvez também exista algum efeito direto da “Habilidade de Aprendizagem Contínua” e da “Mentalidade de Crescimento” na “Adaptabilidade da Força de Trabalho” que não passa pelo “soft skills” ou seja, é independente do “soft skills”(linha vermelha tracejada na figura).
Podemos testar o ajuste de um modelo que inclui esses edges vermelhos versus um modelo que as exclui, e ver qual modelo se ajusta melhor aos dados, ou seja, qual modelo é mais consistente com os padrões de associação que realmente observamos em nossos dados.
Como fazer?
Antes de iniciarmos nos exemplos é importante notar as diferentes sintaxes no pacote lavaan como ~ significa previsão(predict), =~ significa indicador(indicator). E também as definições das palavras(e.g variável exógena, fator etc.)
Clique aqui para mais detalhes sobre as sintaxes usadas no lavaan
fórmulas e sintaxes
~ significa prever ou predict e é usado para regressõ do resultado observado aos preditores observados(e.g. lm(mpg~wt, data = mtcars)).
=~ significa indicador(indicator) e é usada para a variável latente para indicador observado em modelos SEM(e.g. f =~ q + r + s)
~~ significa covariância(e.g. x~~x), que neste caso é variância por está interagindo com ela mesma.
~1 significa intercepto(e.g. x~1 estima média da variável x)
1* significa corrige parametro ou carga(e.g. f =~1*q)
NA* significa liberar o parâmetro ou carga(e.g. f=~NA*q), e é util para substituir o marcados padrão.
a* significa rotular o parâmetro ‘a’ usado para restrições do modelo(e.g. f=~a*q)
tipos de variáveis e resultados
variável observada: é algo que a gente consegue medir ou ver diretamente(e.g. quantas peças um funcionário produz por hora)
variável latente: é algo que a gente não consegue medir diretamente, mas que deduzimos com base em outras coisas(e.g. satisfação no trabalho de alguém).
variável exógena: é uma causa. Ela influencia outra coisa, mas não é influenciada por ela(e.g pense na “experiência” de um funcionário).
variável endógena: é um efeito. Ela é influenciada por outras coisas(e.g a “produtividade” de um funcionário).
modelo de medição: é como a gente liga o que a gente vê (variáveis observadas) com o que a gente não vê diretamente(variáveis latentes).
indicador: é o que a gente usa pra medir algo que não vemos. Se a “satisfação” é o que não vemos, o “número de reclamações” pode ser um indicador.
fator: é o que a gente não vê, mas que é formado por várias coisas que a gente mede(e.g a “qualidade” é um fator, medido por “defeitos”, “rejeitos”, etc).
carga fatorial: é o quanto uma coisa medida contribui para formar o que a gente não vê(e.g. tipo a “força” da ligação).
modelo estrutural: é como a gente mostra as relações de causa e efeito entre as coisas que estudamos.
regression path: é a seta que mostra a influência direta de uma coisa sobre outra.
diagrama
retangulos/quadrados representa que a variável é observada
circulos representa que a variável é latente
traço com seta de um lado representa o caminho da causa e efeito
traço com seta dos dois lados representa a covariância ou variância(quando ela estiver em si mesma)
Caso1 - Prever milhas por galão e tempo de aceleração de veículos
Iremos fazer um modelo path analysis de regressão multivariada (duas variáveis de resposta) com variáveis observadas(neste não terá variáveis latentes), apenas para ilustrar de forma simples o problema e a solução. Para isso usaremos o conjunto de dados mtcars que é bem conhecido por quem usa o R
A especificação do modelo SEM é feito com uma string(em formato de texto), note que foi usado aspas indicado que o formato é texto, onde háduas equações estruturais.
mpg ~ cyl + disp + hp: o consumo de combustível (mpg) é explicado por número de cilindros (cyl), deslocamento (disp) e potência (hp).
qsec ~ disp + hp + wt: o tempo de aceleração (qsec) é explicado por deslocamento (disp), potência (hp) e peso (wt).
Rodar o modelo usando R/RStudio Rstudio/Rstudio (2025), Lavaan package Rosseel (2024), Quarto Publishing “Quarto” (2025) e mostrar os resultados.
# packageslibrary(tidyverse)library(lavaan)library(lavaanPlot)# step1: especificação do modelo SEMmdl_spec_sem_mtcas <-"mpg ~ cyl + disp + hpqsec ~ disp + hp + wt"# step2: rodar o modelo e mostrar resultados# rodar o modelomdl_fit_sem_mtcars <-sem(mdl_spec_sem_mtcas, data = mtcars)# mostrar os resultadossummary(mdl_fit_sem_mtcars, fit.measures =TRUE, standardized =TRUE)
lavaan 0.6-19 ended normally after 32 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 9
Number of observations 32
Model Test User Model:
Test statistic 18.266
Degrees of freedom 2
P-value (Chi-square) 0.000
Model Test Baseline Model:
Test statistic 101.965
Degrees of freedom 9
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.825
Tucker-Lewis Index (TLI) 0.213
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -124.003
Loglikelihood unrestricted model (H1) -114.870
Akaike (AIC) 266.005
Bayesian (BIC) 279.197
Sample-size adjusted Bayesian (SABIC) 251.140
Root Mean Square Error of Approximation:
RMSEA 0.504
90 Percent confidence interval - lower 0.309
90 Percent confidence interval - upper 0.727
P-value H_0: RMSEA <= 0.050 0.000
P-value H_0: RMSEA >= 0.080 1.000
Standardized Root Mean Square Residual:
SRMR 0.041
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
mpg ~
cyl -0.987 0.738 -1.337 0.181 -0.987 -0.293
disp -0.021 0.010 -2.178 0.029 -0.021 -0.435
hp -0.017 0.014 -1.218 0.223 -0.017 -0.190
qsec ~
disp -0.008 0.004 -2.122 0.034 -0.008 -0.559
hp -0.023 0.004 -5.229 0.000 -0.023 -0.849
wt 1.695 0.398 4.256 0.000 1.695 0.908
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.mpg ~~
.qsec 0.447 0.511 0.874 0.382 0.447 0.156
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.mpg 8.194 2.049 4.000 0.000 8.194 0.234
.qsec 0.996 0.249 4.000 0.000 0.996 0.308
Clique aqui para mais detalhes sobre a interpretação dos resultados do modelo
Interpretação da Saída:
1. Informações Básicas do Modelo:
lavaan 0.6-19 ended normally after 32 iterations: O processo de estimação do modelo convergiu com sucesso após 32 iterações. Isso é bom, indica que o algoritmo encontrou uma solução estável.
Estimator ML: O estimador usado foi o de Máxima Verossimilhança (Maximum Likelihood). Este é o estimador padrão e mais comum para SEM quando os dados são aproximadamente normais.
Optimization method NLMINB: O método de otimização usado.
Number of model parameters 9: O modelo possui 9 parâmetros que foram estimados(e.g. os coeficientes de caminho, variâncias residuais, covariâncias).
Number of observations 32: Foi usado um conjunto de dados com 32 observações (linhas), que é o tamanho do conjunto de dados mtcars.
2. Teste do Modelo do Usuário (Model Test User Model):
Este é o teste de qui-quadrado (Chi-square test) do nosso modelo. A hipótese nula (\(H_0\)) deste teste é que o nosso modelo se ajusta perfeitamente aos dados da população. Uma hipótese alternativa (\(H_1\)) é que o modelo não se ajusta perfeitamente.
Test statistic 18.266: O valor do teste de qui-quadrado.
Degrees of freedom 2: Os graus de liberdade do nosso modelo.
P-value (Chi-square) 0.000: O p-valor associado.
Interpretação: Como o p-valor (0.000) é menor que 0.05 (ou qualquer nível de significância usual), nós rejeitamos a hipótese nula. Isso significa que o nosso modelo (o “modelo do usuário”) não se ajusta perfeitamente aos dados observados.
Cuidado: Embora isso possa parecer uma má notícia, o teste de qui-quadrado é muito sensível, especialmente com tamanhos de amostra maiores. Com 32 observações, a rejeição aqui é um sinal de que o modelo não é perfeito. No entanto, em SEM, raramente esperamos um ajuste perfeito. O foco geralmente é em ter um “bom ajuste” ou um “ajuste razoável”, avaliado por outros índices de ajuste.
3. Teste do Modelo de Linha de Base (Model Test Baseline Model):
O modelo de linha de base (baseline model) é um modelo nulo onde todas as variáveis são consideradas não correlacionadas. Serve como um ponto de comparação para o nosso modelo.
Test statistic 101.965
Degrees of freedom 9
P-value 0.000
Interpretação: O modelo de linha de base também não se ajusta bem aos dados (p-valor < 0.05), o que é esperado, pois é um modelo muito restritivo. Este teste é usado principalmente para calcular os índices de ajuste comparativos (CFI, TLI).
4. Modelo do Usuário versus Modelo de Linha de Base (User Model versus Baseline Model):
Esses são índices de ajuste incrementais, que comparam o nosso modelo com o modelo de linha de base.
Comparative Fit Index (CFI) 0.825:
Interpretação: O CFI varia de 0 a 1. Valores acima de 0.90 ou 0.95 são geralmente considerados indicativos de um bom ajuste. Nosso CFI de 0.825 está abaixo dos critérios comuns para um bom ajuste (geralmente > 0.90 ou > 0.95). Isso sugere que o nosso modelo não melhora substancialmente o ajuste em comparação com o modelo nulo o suficiente para ser considerado um “bom” ajuste.
Tucker-Lewis Index (TLI) 0.213:
Interpretação: O TLI (também conhecido como NNFI) é outro índice incremental, também variando geralmente de 0 a 1, com valores > 0.90 ou > 0.95 indicando bom ajuste. Seu TLI de 0.213 é muito baixo, indicando um ajuste pobre do modelo.
Em resumo para CFI e TLI: Ambos os índices sugerem que o nosso modelo não está bem ajustado aos dados.
5. Critérios de Log-Verossimilhança e Informação (Loglikelihood and Information Criteria):
Esses critérios são usados para comparar modelos, favorecendo modelos com melhor ajuste e menor complexidade. Valores menores são geralmente preferíveis.
Loglikelihood user model (H0) -124.003: A log-verossimilhança do nosso modelo.
Loglikelihood unrestricted model (H1) -114.870: A log-verossimilhança do modelo não restrito (também conhecido como modelo saturado), que é o modelo com o melhor ajuste possível aos dados.
Akaike (AIC) 266.005: Critério de Informação de Akaike.
Bayesian (BIC) 279.197: Critério de Informação Bayesiano.
Sample-size adjusted Bayesian (SABIC) 251.140: BIC ajustado para o tamanho da amostra.
Interpretação: Esses valores são mais úteis para comparar nosso modelo com modelos alternativos (modelos aninhados ou não aninhados). Modelos com valores menores de AIC, BIC e SABIC são considerados melhores. Isoladamente, eles não indicam “bom” ou “mau” ajuste.
6. Erro Quadrático Médio da Aproximação (Root Mean Square Error of Approximation - RMSEA):
O RMSEA é um índice de ajuste absoluto que mede o quão mal o modelo se ajusta aos dados. Valores menores indicam melhor ajuste.
RMSEA 0.504:
Interpretação: Um RMSEA < 0.05 é considerado um bom ajuste, entre 0.05 e 0.08 é um ajuste razoável, e > 0.10 é um ajuste pobre. Nosso valor de 0.504 é extremamente alto, indicando um ajuste muito ruim do modelo aos dados.
90 Percent confidence interval - lower 0.309
90 Percent confidence interval - upper 0.727: O intervalo de confiança para o RMSEA é muito amplo e totalmente acima de 0.08, reforçando o mau ajuste.
P-value H_0: RMSEA <= 0.050 0.000: Este é o p-valor para o teste da hipótese nula de que o RMSEA é menor ou igual a 0.05. Como é 0.000, rejeitamos essa hipótese.
P-value H_0: RMSEA >= 0.080 1.000: Este é o p-valor para o teste da hipótese nula de que o RMSEA é maior ou igual a 0.08. Como é 1.000, não podemos rejeitar essa hipótese, o que significa que é muito provável que seu RMSEA seja realmente >= 0.08.
Em resumo para RMSEA: O RMSEA confirma que o modelo tem um ajuste muito pobre aos dados.
Tabela de Regressão
É a parte mais importante da saída para entender as relações específicas do modelo SEM. Ela detalha os coeficientes estimados para cada caminho (regressão), covariância e variância**
1. Informações sobre Erros Padrão (Standard errors):
Standard errors Standard: Indica que os erros padrão foram calculados usando o método padrão (não robusto).
Information Expected: O tipo de matriz de informação utilizada na estimação (esperada).
Information saturated (h1) model Structured: Refere-se a como a matriz de informação é tratada para o modelo saturado (h1).
Interpretação: Essas são informações técnicas sobre como os erros padrão e os testes de significância foram calculados. Geralmente não é necessário se aprofundar muito nisso, a menos que haja problemas de convergência ou preocupações com a normalidade dos dados.
2. Regressões (Regressions):
Esta seção mostra os efeitos diretos (caminhos) de uma variável sobre outra, semelhantes aos coeficientes de regressão.
Estimate: O coeficiente de regressão(não padronizado). Representa a mudança na variável dependente para cada unidade de mudança na variável preditora, mantendo as outras preditoras constantes.
Std.Err: O erro padrão do coeficiente estimado.
z-value: O valor Z do teste de Wald, que é o Estimate dividido pelo Std.Err. É usado para testar a significância estatística do coeficiente.
P(>|z|): O p-valor associado ao valor Z. Se for menor que seu nível de significância (geralmente 0.05), o coeficiente é considerado estatisticamente significativo.
Std.lv: Coeficientes padronizados com base apenas nas variáveis latentes (se houver). Neste modelo, como você só tem variáveis observadas, será o mesmo que Estimate.
Std.all: Coeficientes padronizados com base em todas as variáveis (observadas e latentes). Estes são os que você vê no diagrama e são os mais úteis para comparar a força relativa dos efeitos. Eles variam de -1 a 1.
Detalhes da Interpretação:
a) mpg ~ cyl (mpg é predito por cyl): * Estimate = -0.987: Para cada aumento de 1 cilindro, o mpg diminui em 0.987 unidades. * P(>|z|) = 0.181: Não é significativo (p > 0.05). Isso significa que o número de cilindros não tem um efeito direto estatisticamente significativo sobre mpg, após contabilizar as outras variáveis no modelo para mpg. * Std.all = -0.293: Um efeito padronizado fraco a moderado, mas não significativo. (Corresponde a -0.29 no diagrama).
b) mpg ~ disp (mpg é predito por disp): * Estimate = -0.021: Para cada aumento de 1 unidade em disp, o mpg diminui em 0.021 unidades. * P(>|z|) = 0.029: Significativo (p < 0.05). disp tem um efeito direto negativo estatisticamente significativo sobre mpg. * Std.all = -0.435: Um efeito padronizado moderado e significativo. (Corresponde a -0.44 no diagrama).
c) mpg ~ hp (mpg é predito por hp): * Estimate = -0.017: Para cada aumento de 1 unidade em hp, o mpg diminui em 0.017 unidades. * P(>|z|) = 0.223: Não é significativo (p > 0.05). hp não tem um efeito direto estatisticamente significativo sobre mpg após contabilizar as outras variáveis. * Std.all = -0.190: Um efeito padronizado fraco e não significativo. (Corresponde a -0.19 no diagrama).
d) qsec ~ disp (qsec é predito por disp): * Estimate = -0.008: Para cada aumento de 1 unidade em disp, o qsec diminui em 0.008 unidades. * P(>|z|) = 0.034: Significativo (p < 0.05). disp tem um efeito direto negativo estatisticamente significativo sobre qsec. * Std.all = -0.559: Um efeito padronizado forte e significativo. (Corresponde a -0.56 no diagrama).
e) qsec ~ hp (qsec é predito por hp): * Estimate = -0.023: Para cada aumento de 1 unidade em hp, o qsec diminui em 0.023 unidades. * P(>|z|) = 0.000: Altamente significativo (p < 0.001). hp tem um efeito direto negativo muito forte e estatisticamente significativo sobre qsec. * Std.all = -0.849: Um efeito padronizado muito forte e significativo. (Corresponde a -0.85 no diagrama).
f) qsec ~ wt (qsec é predito por wt): * Estimate = 1.695: Para cada aumento de 1 unidade em wt, o qsec aumenta em 1.695 unidades. * P(>|z|) = 0.000: Altamente significativo (p < 0.001). wt tem um efeito direto positivo muito forte e estatisticamente significativo sobre qsec. * Std.all = 0.908: Um efeito padronizado muito forte e significativo. (Corresponde a 0.91 no diagrama).
Resumo das Regressões: * Para mpg, apenas disp tem um efeito direto significativo (e negativo). * Para qsec, disp, hp e wt têm efeitos diretos significativos. hp (negativo) e wt (positivo) são os preditores mais fortes de qsec.
3. Covariâncias (Covariances):
Esta seção mostra as covariâncias estimadas entre variáveis que não têm uma relação causal direta modelada (ou entre os resíduos das variáveis endógenas).
.mpg ~~ .qsec (Covariância entre os resíduos de mpg e qsec):
Estimate = 0.447: A covariância não padronizada dos resíduos.
P(>|z|) = 0.382: Não é significativo (p > 0.05).
Std.all = 0.156: Uma correlação residual padronizada fraca e não significativa. (Corresponde a 0.16 no diagrama, que é a correlação entre os resíduos, não as variáveis brutas).
Interpretação: A covariância (ou correlação) entre os resíduos de mpg e qsec não é estatisticamente significativa. Isso significa que, após contabilizar os efeitos das variáveis preditoras (cyl, disp, hp para mpg; disp, hp, wt para qsec), qualquer variância restante em mpg e qsec não está significativamente relacionada entre si.
4. Variâncias (Variances):
Esta seção mostra as variâncias estimadas para as variáveis exógenas(chamada de causas ou variáveis preditoras) e as variâncias residuais para as variáveis endógenas(chamadas de efeito ou variáveis de resposta).
.mpg (Variância residual de mpg):
Estimate = 8.194: A variância não padronizada do resíduo de mpg.
P(>|z|) = 0.000: Altamente significativo, o que é esperado para variâncias.
Std.all = 0.234: A variância residual padronizada (1 - R-quadrado). Isso significa que 23.4% da variância de mpg não é explicada pelas preditoras no modelo. Consequentemente, as preditoras (cyl, disp, hp) explicam 1 - 0.234 = 0.766 ou 76.6% da variância em mpg (R-quadrado para mpg). (Corresponde a 0.23 no diagrama).
.qsec (Variância residual de qsec):
Estimate = 0.996: A variância não padronizada do resíduo de qsec.
P(>|z|) = 0.000: Altamente significativo.
Std.all = 0.308: A variância residual padronizada (1 - R-quadrado). Isso significa que 30.8% da variância de qsec não é explicada pelas preditoras no modelo. Consequentemente, as preditoras (disp, hp, wt) explicam 1 - 0.308 = 0.692 ou 69.2% da variância em qsec (R-quadrado para qsec). (Corresponde a 0.31 no diagrama).
Interpretação: As variâncias residuais indicam a proporção da variância das variáveis dependentes que não é explicada pelo modelo. Os valores padronizados (Std.all) fornecem o complementar do R-quadrado. nosso modelo explica uma proporção razoável da variância em ambas as variáveis dependentes.
Considerações Finais:
Lembre-se da interpretação anterior sobre o ajuste geral do modelo. Embora alguns caminhos individuais sejam estatisticamente significativos e os Rs-quadrados sejam razoáveis, os índices de ajuste globais (CFI, TLI, RMSEA) indicaram que o modelo como um todo não se ajusta bem aos dados. Isso significa que, embora as relações específicas que você encontrou sejam interessantes, a estrutura geral do nosso modelo pode não ser a melhor representação dos dados, possivelmente devido ao pequeno tamanho da amostra ou a um modelo teórico incompleto/incorreto.
Em resumo, nosso modelo atual não se ajusta bem aos dados. A primeira etapa é sempre revisar a teoria por trás do nosso modelo e a especificação no lavaan. Dada a pequena amostra do mtcars, é desafiador construir um modelo SEM robusto com este conjunto de dados, eu apenas usei ele para facilitar o entendimento para quem está vendo esse conteúdo pela primeira vez, mas que já conheça o mtcars de outros exemplos.
Conclusão Geral e Recomendações:
Com base em todos os índices de ajuste (Chi-quadrado, CFI, TLI, RMSEA), nosso modelo atual apresenta um ajuste muito pobre aos dados do mtcars. Isso significa que as relações e a estrutura que nós hipotetizamos em nosso diagrama (e que o lavaan tentou ajustar) não representam bem as covariâncias observadas no conjunto de dados.
O que fazer a seguir?
Revisar o Modelo Teórico:
nosso modelo SEM deve ser baseado em teoria. As relações que desenhamos fazem sentido conceitualmente?
Há alguma variável importante faltando no modelo que poderia explicar melhor mpg ou qsec?
Será que incluímos todas as covariâncias entre as variáveis preditoras(cyl, disp, hp, wt) que são esperadas? (Pelo diagrama, parece que sim, mas verificar se o modelo lavaan as especificou corretamente, é uma boa coisa a se fazer).
Verificar Especificação do Modelo:
Certificar de que a sintaxe do lavaan reflete exatamente o diagrama que nós pretendiamos testar. Às vezes, pequenos erros de digitação ou omissões podem levar a um ajuste ruim.
Se nós usamos um atalho como x ~~ y para covariância ou y ~ x para regressão, confirir se não há setas ou covariâncias que deveriam estar lá mas não foram especificadas, também é uma boa prática.
Explorar Modificações, mas com Cuidado:
O lavaan pode fornecer índices de modificação (modindices()) que sugerem quais parâmetros (caminhos ou covariâncias) poderiam ser adicionados ao modelo para melhorar o ajuste.
Importante: Use índices de modificação com muita cautela e apenas se as modificações fizerem sentido teórico. Fazer mudanças apenas para melhorar o ajuste sem base teórica pode levar a um modelo superajustado aos dados da amostra e que não generaliza bem.
Tamanho da Amostra:
Com 32 observações, nós temos um tamanho de amostra muito pequeno para SEM. Modelos SEM geralmente exigem amostras maiores (centenas de observações) para ter poder estatístico adequado e para que os índices de ajuste funcionem de forma confiável. Um tamanho de amostra pequeno pode inflar o qui-quadrado e dificultar a obtenção de um bom ajuste, mesmo que o modelo seja teoricamente correto. No caso do mtcars, que tem apenas 32 carros, as limitações do conjunto de dados são um fator importante.
Multicolinearidade:
No diagrama, vimos correlações muito altas entre cyl, disp, hp, wt. Isso também pode ser observado, se nos plotarmos um gráfico de correlação. Embora SEM possa lidar com isso melhor do que regressão múltipla tradicional, correlações extremamente altas ainda podem dificultar a estimação ou interpretação dos efeitos diretos.
Conexão com o Diagrama abaixo
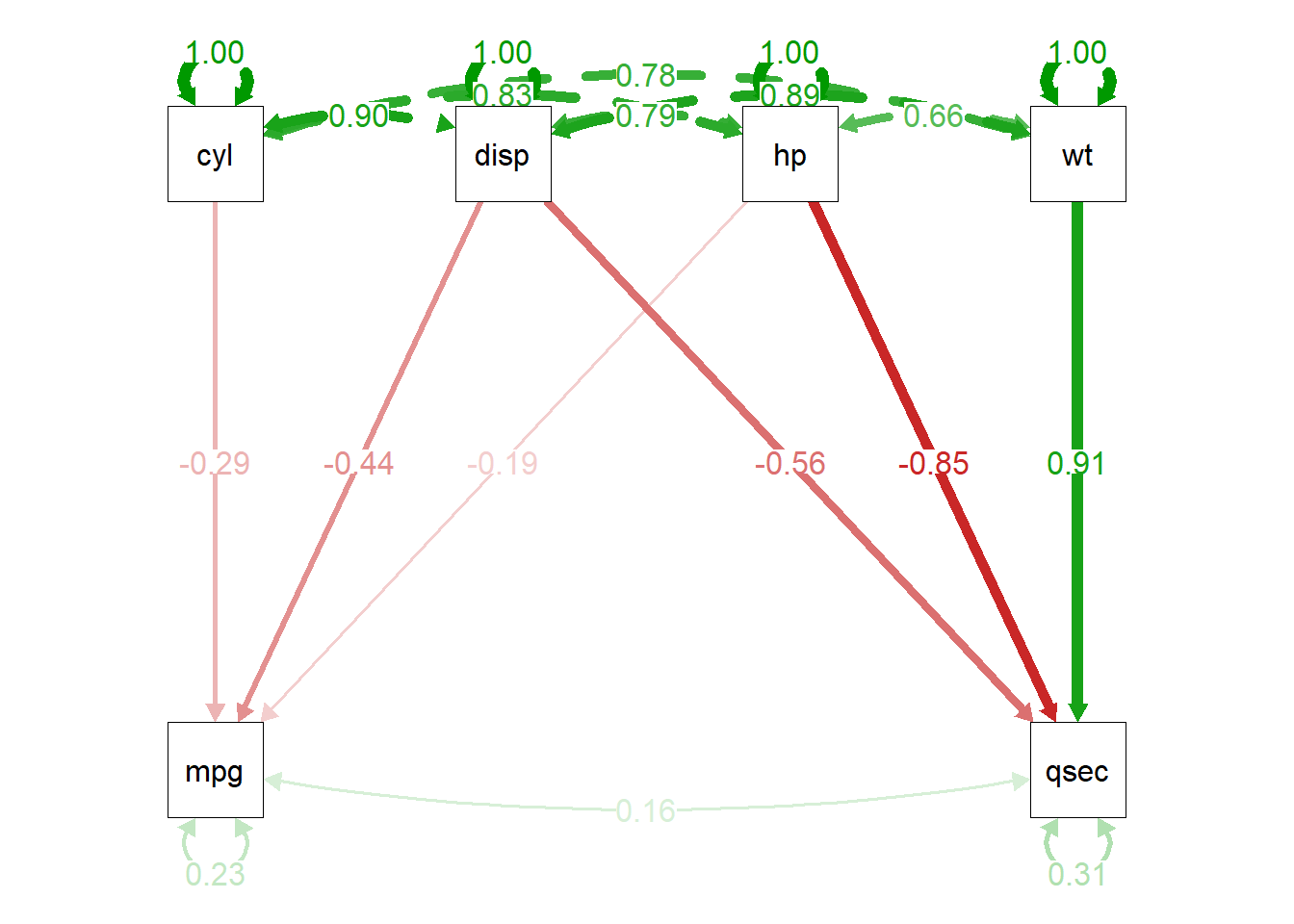
Os valores na coluna Std.all correspondem diretamente aos números exibidos nas setas do nosso diagrama (semPlot). A espessura das setas no diagrama visualmente representa a magnitude desses Std.all. A cor (verde/vermelho) reflete o sinal do Estimate (positivo/negativo).
Agora, vamos plotar os resultados no diagrama usando o pacote semPlotEpskamp (2025)
library(semPlot)# Gerar o diagrama de caminhossemPaths(mdl_fit_sem_mtcars, what ="std", # mostra coeficientes padronizadoslayout ="tree", # organiza em formato de árvoreedge.label.cex =1.2, # tamanho dos rótulossizeMan =8, # tamanho dos nóssizeLat =10, # tamanho das variáveis latentes(não tem nesse modelo)nCharNodes =0)
Clique aqui pra expandir se precisar da interpretação do gráfico
O diagrama de caminho (path diagram) acima, representa as relações hipotéticas entre variáveis usando o conjunto de dados mtcars.
Visão Geral do Diagrama:
Variáveis Observadas (Retângulos): representa uma variável observada do conjunto de dados mtcars(e.g cyl(número de cilindros), disp(cilindrada),hp(potência),wt(peso do veículo), mpg(milhas por galão), qsec(tempo de 1/4 de milha). Se tivessemos variáveis latentes elas apareceriam em círculos.
Setas e Linhas: representam relações causais ou diretivas (regressões), enquanto as linhas bidirecionais curvas representam covariâncias ou correlações.
Cores: Verde indica uma relação positiva, enquanto a vermelha, relação negativa.
Espessura da Linha/Seta: É proporcional à magnitude do coeficiente de caminho (seja ele um coeficiente de regressão ou uma correlação). Linhas mais grossas indicam relações mais fortes.
Números nas Setas/Linhas: são os coeficientes de caminho padronizados (standardized path coefficients), que são análogos a coeficientes de regressão padronizados ou correlações. Eles variam de -1 a 1. Onde valores próximos a 0 indicam relações fracas e valores próximos a 1 (ou -1) indicam relações fortes.
Interpretação detalhada por seções:
1. Relações entre as variáveis de “características do carro” (Topo):
Setas Bidirecionais Curvas na Parte Superior (entre cyl, disp, hp, wt): Estas representam as correlações entre essas variáveis de características do carro. Todas são verdes e têm valores altos, indicando fortes correlações positivas.
cyl <-> cyl (1.00): Isso é o “erro” ou variância não explicada da própria variável. Em modelos SEM, geralmente é a variância residual ou a variância de um erro, mas para variáveis exógenas (sem setas apontando para elas), pode representar a variância total. No entanto, o semPlot pode desenhar isso como a variância total de uma variável quando não há preditores, ou a variância residual de uma variável endógena. Neste caso, para cyl, disp, hp, wt que parecem ser variáveis exógenas (ou seja, suas causas não são modeladas aqui, elas são as preditoras), esse 1.00 geralmente representa que 100% da variância delas é explicada por si mesmas no contexto de não serem preditas por outras variáveis no modelo, ou simplesmente sua variância total (que é 1 em uma escala padronizada).
cyl <-> disp: Correlação de 0.90 (forte, positiva). Carros com mais cilindros tendem a ter maior cilindrada.
disp <-> hp: Correlação de 0.83 (forte, positiva). Carros com maior cilindrada tendem a ter maior potência.
disp <-> disp (1.00): O mesmo que para cyl.
hp <-> hp (1.00): O mesmo.
hp <-> wt: Correlação de 0.79 (forte, positiva). Carros com maior potência tendem a ser mais pesados.
disp <-> wt: Correlação de 0.78 (forte, positiva). Carros com maior cilindrada tendem a ser mais pesados.
wt <-> wt (1.00): O mesmo.
cyl <-> hp (não mostrado diretamente, mas inferido através de disp).
cyl <-> wt (não mostrado diretamente, mas inferido).
hp <-> cyl (0.89): Forte correlação positiva.
wt <-> hp (0.66): Correlação positiva.
Em resumo: Essas quatro variáveis (cyl, disp, hp, wt) são altamente correlacionadas entre si. Isso é esperado, pois elas são características intrínsecas do motor e do carro que geralmente andam juntas.
2. Relações entre Variáveis de Características do Carro e mpg (Consumo):
cyl -> mpg: Coeficiente de -0.29 (vermelho, fraco a moderado, negativo). Carros com mais cilindros tendem a ter menor mpg (pior consumo de combustível).
disp -> mpg: Coeficiente de -0.44 (vermelho, moderado, negativo). Carros com maior cilindrada tendem a ter menor mpg.
hp -> mpg: Coeficiente de -0.19 (vermelho, fraco, negativo). Carros com maior potência tendem a ter menor mpg.
wt -> mpg: Não há seta direta de wt para mpg neste modelo. Isso sugere que o modelo não assume uma relação direta de wt para mpg APÓS contabilizar as outras variáveis, ou a relação não foi estatisticamente significativa para ser incluída ou é indireta.
Em resumo: Cilindros, cilindrada e potência estão negativamente associadas ao consumo de combustível. Carros com características de motor mais “potentes” ou “maiores” tendem a consumir mais combustível (menor mpg). disp tem o efeito direto negativo mais forte em mpg.
3. Relações entre Variáveis de Características do Carro e qsec (Tempo de 1/4 de Milha):
disp -> qsec: Coeficiente de -0.56 (vermelho, moderado a forte, negativo). Carros com maior cilindrada tendem a ter um tempo de 1/4 de milha menor (ou seja, são mais rápidos).
hp -> qsec: Coeficiente de -0.85 (vermelho, muito forte, negativo). Carros com maior potência tendem a ter um tempo de 1/4 de milha significativamente menor (são muito mais rápidos).
wt -> qsec: Coeficiente de 0.91 (verde, muito forte, positivo). Carros mais pesados tendem a ter um tempo de 1/4 de milha maior (ou seja, são mais lentos).
Em resumo: Cilindrada e potência contribuem para um carro mais rápido (menor qsec), com a potência (hp) sendo o fator mais influente. O peso (wt), por outro lado, torna o carro mais lento (maior qsec), com uma influência igualmente forte.
4. Relação entre mpg e qsec:
mpg <-> qsec: Coeficiente de 0.16 (verde, fraco, positivo). Há uma correlação positiva fraca entre mpg e qsec. Carros com melhor consumo de combustível tendem a ter um tempo de 1/4 de milha ligeiramente maior (são um pouco mais lentos). É importante notar que esta é uma correlação bidirecional, não uma relação causal direta no sentido de mpg causando qsec ou vice-versa neste modelo específico. Pode ser que variáveis não modeladas ou efeitos indiretos expliquem essa correlação.
5. Variância Residual (Loops nas Variáveis Dependentes):
mpg <-> mpg (0.23): Este é o coeficiente de variância residual para mpg. Significa que 23% da variância de mpg NÃO é explicada pelas variáveis preditoras (cyl, disp, hp) incluídas no modelo para mpg. Ou, em outras palavras, as variáveis cyl, disp, hp explicam 1 - 0.23 = 0.77 ou 77% da variância em mpg (o R-quadrado).
qsec <-> qsec (0.31): Este é o coeficiente de variância residual para qsec. Significa que 31% da variância de qsec NÃO é explicada pelas variáveis preditoras (disp, hp, wt) incluídas no modelo para qsec. Portanto, disp, hp, wt explicam 1 - 0.31 = 0.69 ou 69% da variância em qsec.
Conclusões Gerais e Interpretação do Modelo:
Este modelo tenta explicar o consumo de combustível (mpg) e o desempenho de 1/4 de milha (qsec) usando características do motor e peso do carro.
Consumo de Combustível (mpg): É predominantemente influenciado negativamente por disp e cyl, e um pouco por hp. Carros com motores maiores/mais potentes tendem a ser menos eficientes em termos de combustível.
Desempenho de 1/4 de Milha (qsec): É fortemente influenciado pela potência (hp) e peso (wt), e também pela cilindrada (disp). Mais potência e menor cilindrada (para motores mais eficientes) levam a carros mais rápidos, enquanto maior peso torna os carros mais lentos. hp e wt têm os efeitos mais proeminentes.
Correlações Elevadas entre Preditoras: As altas correlações entre cyl, disp, hp, e wt são um ponto importante. Em modelos de regressão múltipla, isso poderia indicar multicolinearidade. Em SEM, isso é explicitamente modelado pelas covariâncias. Isso significa que essas variáveis não são independentes em seus efeitos, e os efeitos diretos que vemos (cyl -> mpg, disp -> mpg, etc.) são os efeitos após contabilizar a inter-relação entre as preditoras.
Poder Explicativo: O modelo explica uma grande parte da variância em mpg (77%) e qsec (69%), o que é bastante razoável.
Este diagrama oferece uma representação visual clara das relações entre as variáveis, permitindo entender rapidamente quais fatores são mais influentes e em que direção. As setas mais espessas e os coeficientes de maior magnitude (-0.85 de hp para qsec, 0.91 de wt para qsec, 0.90 de cyl para disp) são os pontos-chave de atenção para as relações mais fortes.
Caso2 - Estudo de impacto da satisfação no trabalho sobre a produtividade, mediado pela motivação
Vamos gerar dados simulados para este modelo.
Especificar(definir) o modeo SEM. A especificação do modelo SEM é feito com uma string(em formato de texto nota que foi usado aspas ou apóstrofos)
Definir as variáveis latentes
Satisfação no trabalho (medida por perguntas sobre ambiente, salário, reconhecimento)
Motivação (medida por perguntas sobre engajamento, metas, esforço)
Produtividade (medida por desempenho, entregas, qualidade)
Definir as equações estruturais
Satisfação → Motivação → Produtividade
Rodar o modelo usando o pacote lavaan e mostar os resultados arrumados usando os pacotes broomRobinson, Hayes, and Couch (2025) e gtIannone et al. (2025)
Rodar o modelo e mostrar os resultados via summary function e também resultados arrumados usando os pacotes broom e gt.
# step3: rodar o modelo e mostrar os resultads# Rodar o modelomdl_fit_sem_impact_motiv_prod <-sem(mdl_fit_spec_impact_motiv_prod,data = dados_produtiv)# Mostrar resultados via summarysummary(mdl_fit_sem_impact_motiv_prod,fit.measures =TRUE, standardized =TRUE)
lavaan 0.6-19 ended normally after 43 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 20
Number of observations 300
Model Test User Model:
Test statistic 24.186
Degrees of freedom 25
P-value (Chi-square) 0.509
Model Test Baseline Model:
Test statistic 3557.984
Degrees of freedom 36
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 1.000
Tucker-Lewis Index (TLI) 1.000
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2549.336
Loglikelihood unrestricted model (H1) -2537.243
Akaike (AIC) 5138.672
Bayesian (BIC) 5212.748
Sample-size adjusted Bayesian (SABIC) 5149.320
Root Mean Square Error of Approximation:
RMSEA 0.000
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.044
P-value H_0: RMSEA <= 0.050 0.977
P-value H_0: RMSEA >= 0.080 0.000
Standardized Root Mean Square Residual:
SRMR 0.018
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Satisfacao =~
Satisfacao1 1.000 0.943 0.999
Satisfacao2 0.970 0.034 28.678 0.000 0.915 0.881
Satisfacao3 0.977 0.035 27.822 0.000 0.922 0.873
Motivacao =~
Motivacao1 1.000 1.183 1.009
Motivacao2 0.986 0.025 38.792 0.000 1.166 0.915
Motivacao3 0.994 0.026 38.198 0.000 1.176 0.913
Produtividade =~
Produtividade1 1.000 1.296 0.998
Produtividade2 1.005 0.022 45.593 0.000 1.303 0.943
Produtividade3 1.018 0.023 43.379 0.000 1.319 0.936
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Motivacao ~
Satisfacao 0.629 0.063 10.038 0.000 0.501 0.501
Produtividade ~
Motivacao 0.684 0.049 13.890 0.000 0.624 0.624
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.Satisfacao1 0.002 0.014 0.118 0.906 0.002 0.002
.Satisfacao2 0.241 0.024 10.155 0.000 0.241 0.224
.Satisfacao3 0.264 0.025 10.386 0.000 0.264 0.237
.Motivacao1 -0.025 0.012 -2.076 0.038 -0.025 -0.018
.Motivacao2 0.263 0.024 10.946 0.000 0.263 0.162
.Motivacao3 0.276 0.025 11.023 0.000 0.276 0.166
.Produtividade1 0.006 0.012 0.463 0.643 0.006 0.003
.Produtividade2 0.213 0.021 9.973 0.000 0.213 0.111
.Produtividade3 0.245 0.024 10.332 0.000 0.245 0.123
Satisfacao 0.890 0.074 12.002 0.000 1.000 1.000
.Motivacao 1.048 0.085 12.375 0.000 0.749 0.749
.Produtividade 1.025 0.084 12.171 0.000 0.610 0.610
# Mostrar resultados arrumados usando broom::tidy() e broom::glance()# coeficientes de regressão (loadings)tidy(mdl_fit_sem_impact_motiv_prod) %>%filter(op=="=~") %>% gt::gt()
term
op
estimate
std.error
statistic
p.value
std.lv
std.all
Satisfacao =~ Satisfacao1
=~
1.0000000
0.00000000
NA
NA
0.9433211
0.9990669
Satisfacao =~ Satisfacao2
=~
0.9700618
0.03382592
28.67806
0
0.9150797
0.8811103
Satisfacao =~ Satisfacao3
=~
0.9770718
0.03511884
27.82187
0
0.9216924
0.8734059
Motivacao =~ Motivacao1
=~
1.0000000
0.00000000
NA
NA
1.1831000
1.0089639
Motivacao =~ Motivacao2
=~
0.9858050
0.02541238
38.79230
0
1.1663058
0.9153346
Motivacao =~ Motivacao3
=~
0.9940990
0.02602470
38.19828
0
1.1761185
0.9129636
Produtividade =~ Produtividade1
=~
1.0000000
0.00000000
NA
NA
1.2963707
0.9983183
Produtividade =~ Produtividade2
=~
1.0050916
0.02204492
45.59289
0
1.3029712
0.9426245
Produtividade =~ Produtividade3
=~
1.0178094
0.02346338
43.37864
0
1.3194583
0.9363450
# principais medidas de ajusteglance(mdl_fit_sem_impact_motiv_prod) %>% gt::gt()
agfi
AIC
BIC
cfi
chisq
npar
rmsea
rmsea.conf.high
srmr
tli
converged
estimator
ngroups
missing_method
nobs
norig
nexcluded
0.9693424
5138.672
5212.748
1
24.18603
20
0
0.04444163
0.01832338
1.000333
TRUE
ML
1
listwise
300
300
0
Resultados
Cargas fatoriais mostrando como cada indicador representa sua variável latente.
Coeficientes padronizados das relações entre Satisfacao, Motivacao e Produtividade.
Índices de ajuste como RMSEA, CFI, TLI para avaliar a qualidade do modelo.
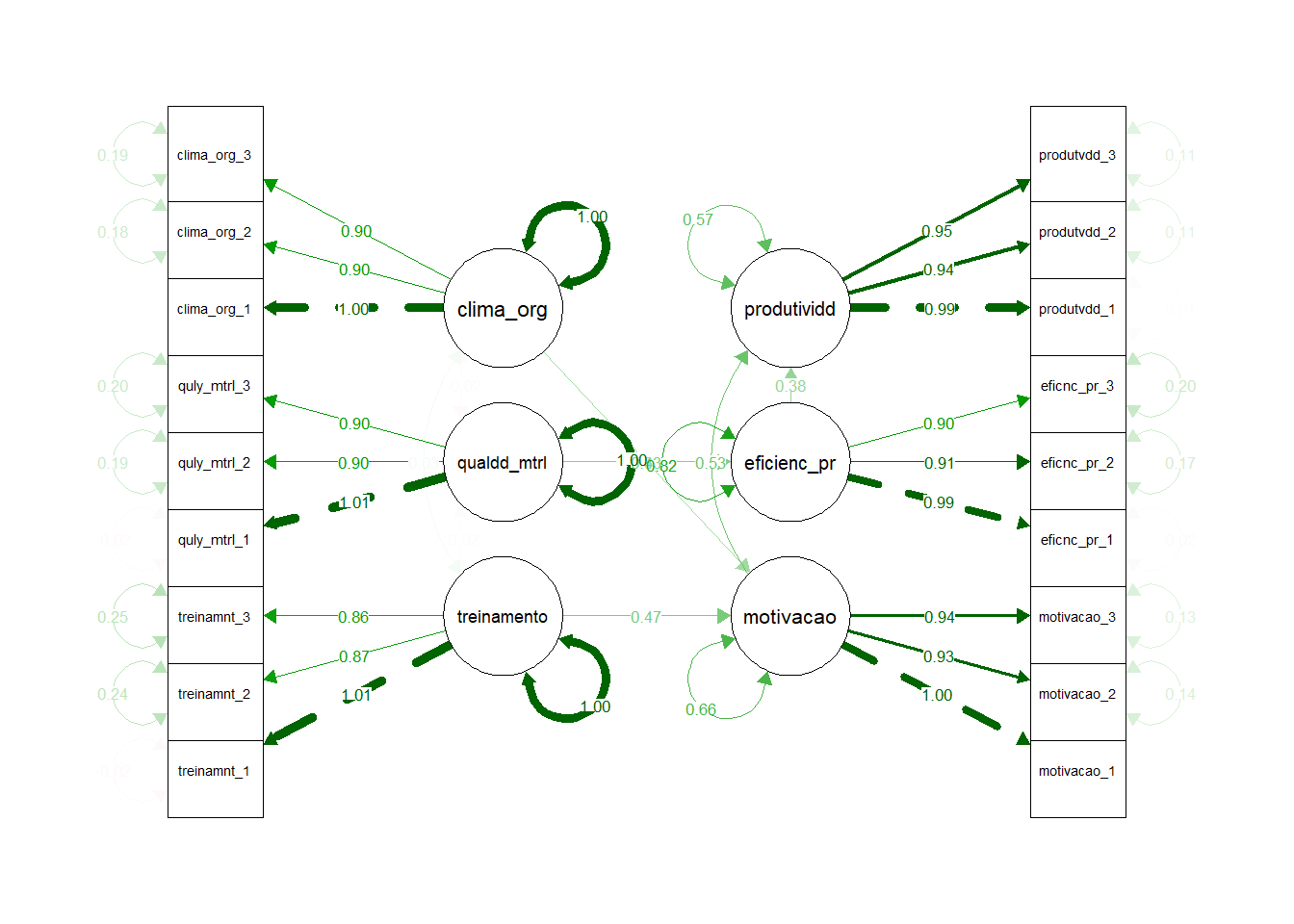
Caso3 - Exemplo em manufatura onde queremos entender por que uma linha de montagem está com baixa produtividade. Suspeitamos que isso tem a ver com treinamento de operadores, qualidade das matérias primas e clima organizacional
Esses fatores não afetam diretamente a produtividade, mas influenciam a motivação e eficiência operacional, que por sua vez afetam a produtividade.
Vamos simular uma fábrica com as variáveis treinamento, qualidade materia prima, clima organizacional, motivação, eficiência operacional e produtividade e gerar um gráfico de correlações.
Vamos definir o modelo SEM com relações causais entre essa variáveis.
Ajustar o modelo e gerar um resumo com cargas fatoriais, coeficientes padronizados, índices de ajustes(e.g. CFI, RMSEA, etc)
Implementar o modelo no R
Mostrar os resultados no diagrama
Gerar os dados de produtividade e plotar as correlações usando corrr package Kuhn, Jackson, and Cimentada (2022)
library(semPlot)# step5: gerar o diagrama com os resultados.semPlot::semPaths(mdl_fit_produtividade,rotation =2,what ="std",layout ="tree",sizeMan =8,sizeLat =10,nCharNodes =11 )
Caso4 - Estudar os efeitos da formação acadêmica no desempenho dos alunos
Este exemplo será feito com o conjunto de dados apresentado por Johnny Lin no seminário UCLA Office of Advanced Research Computing (2021)
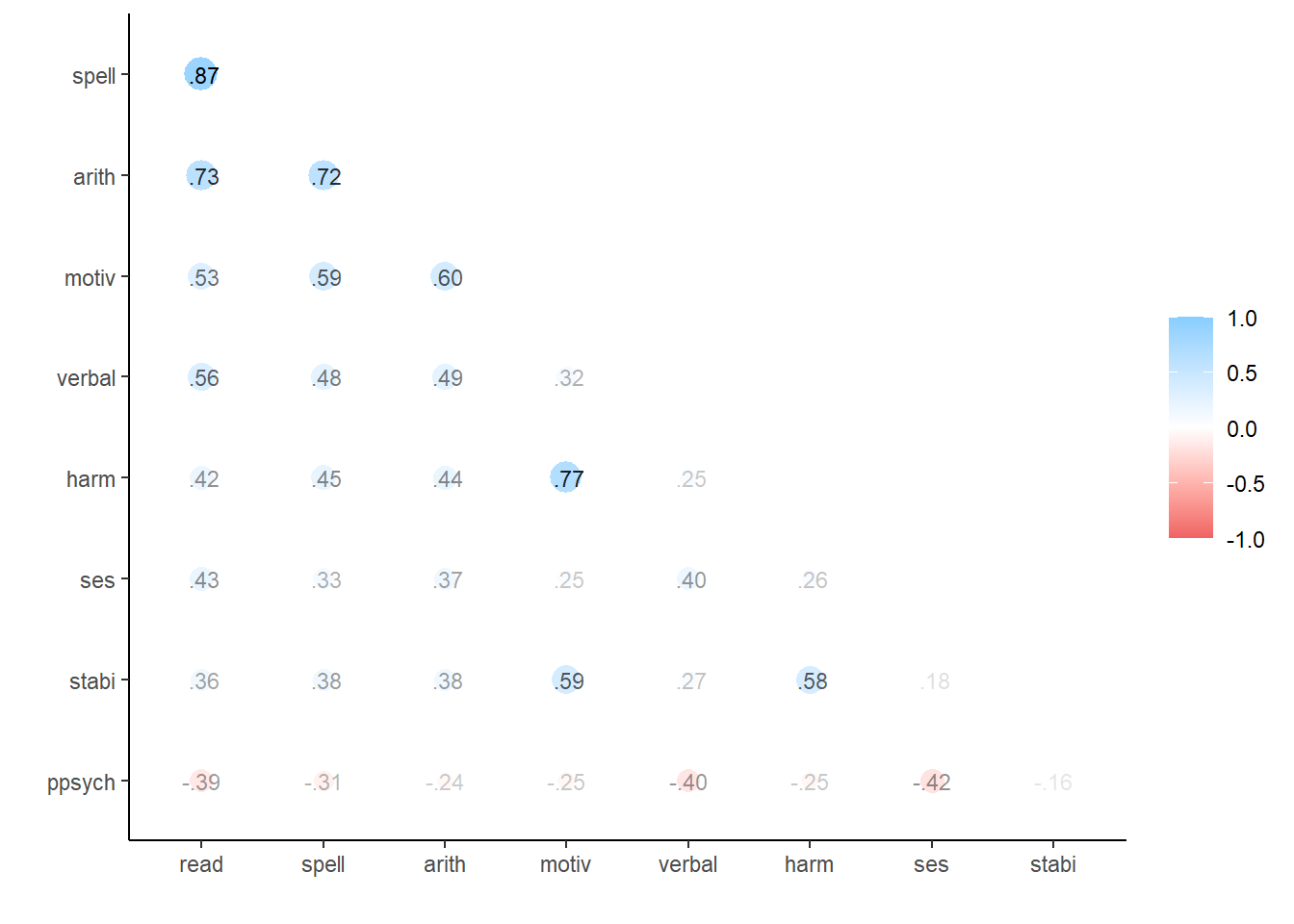
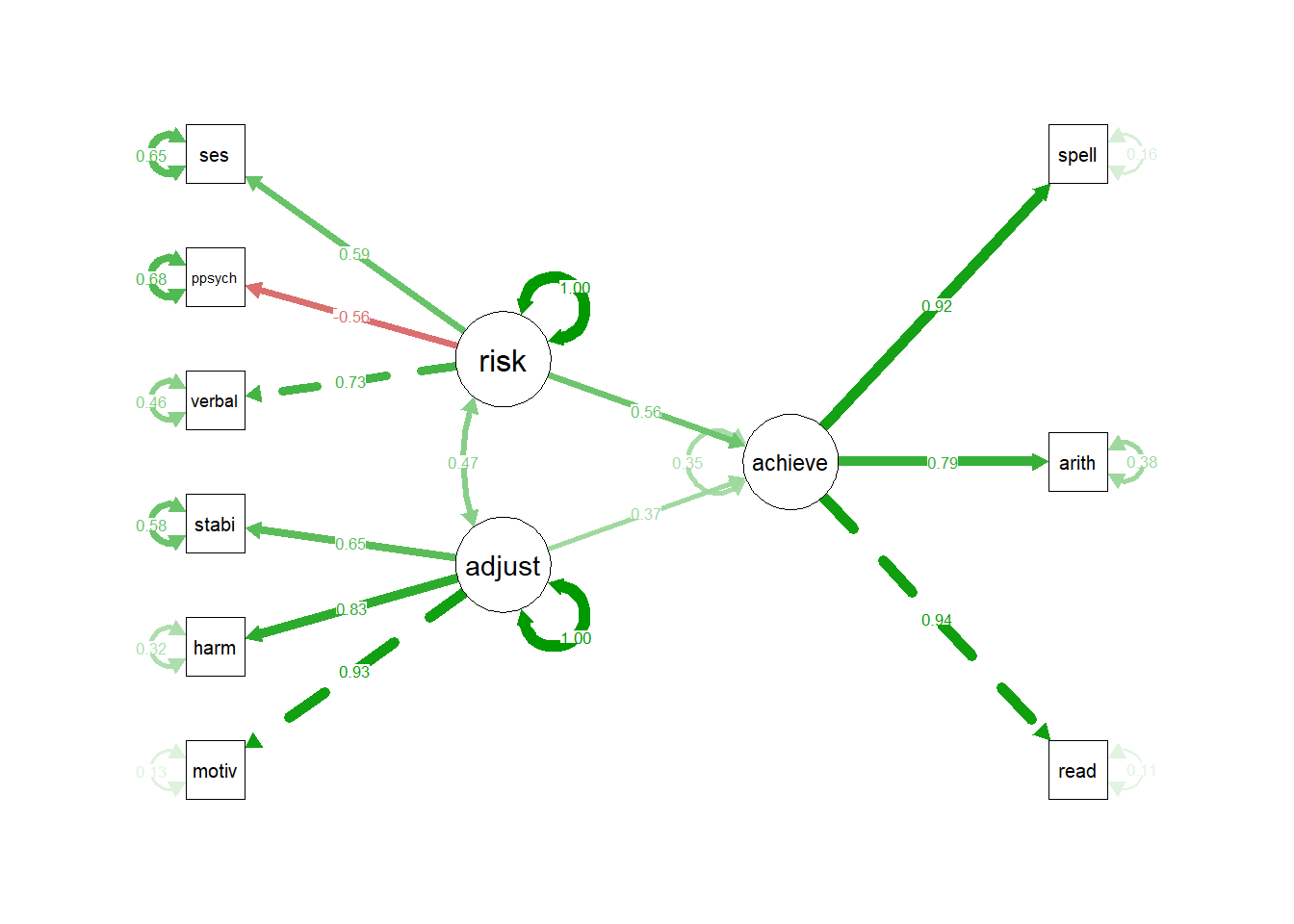
Imagine que você é um pesquisador investigando os impactos da formação acadêmica dos estudantes no seu desempenho escolar. O laboratório coletou os dados de 500 alunos com 9 variáveis observadas sendo motivação(motiv), harmonia(harm), estabilidade(stabi), psicologia parental negativa(ppsych), nível sócio econômico(ses), qi verbal(verbal), leitura(read), aritmética(arith) e ortografia(spell). É formulada a hipótese acerca de três construtos latentes sendo ajuste, risco, conquista, os quais são avaliados conforme o seguinte mapeamento de livro de códigos:
Tabela de medidas
Adjust (Ajuste)
Risk (Risco)
Achieve (Conquista)
motiv
ppsych
read
harm
ses
arith
stabi
verbal
spell
No diagrama abaixo duas variáveis latentes exógenas risk e ajust são estimadas a partir dos indicadores observáveis ses, ppsych, verbal, stabil,harm, motiv. Em seguida, são analisados as relações estruturais com uma variável latente endógena achieve que é estimada pelos indicadores spell, arith e read.
Exemplo do diagrama do modelo SEM
Vamos importar os dados e gerar as correlações
Definir o modelo SEM com relações causais entre as variáveis.
Ajustar o modelo e gerar um resumo com cargas fatoriais, coeficientes padronizados, índices de ajustes(e.g. CFI, RMSEA, etc)
Mostrar os resultados no diagrama
Importando os dados e gerando as correlações.
# carregar as packageslibrary(tidyverse)library(corrr)# step1: importar dados e gerar correlacoes# importar os dadosdata_stud <-read.csv("https://stats.idre.ucla.edu/wp-content/uploads/2021/02/worland5.csv")# plotar as correlaçõesdata_stud %>% corrr::correlate() %>% corrr::rearrange() %>% corrr::shave() %>% corrr::rplot(print_cor =TRUE)
Definir o modelo SEM com relações causais entre essa variáveis.
Depois de construir e validar o modelo SEM, ele pode ser usado para:
Tomada de decisão baseada em evidências como priorizar ações de melhoria com base em dados(e.g investir mais em treinamento se ele tiver alto impacto na produtividade, melhorar políticas de RH).
Apoiar decisões estratégias com evidências estatísticas.
Comunicar resultados de forma clara para diretoria e equipes operacionais.
Integrar SEM com sistemas de qualidade e melhoria contínua(e.g Six Sigma, Lean, TPM)
Publicações científicas que testam teorias complexas.
Desenvolvimento de produtos ou serviços com base em fatores que influenciam comportamento do consumidor.
Avaliação de programas sociais ou educacionais.
Qual resultado?
Mapeamento claro das causas reais de problemas ou oportunidades.
Modelos visuais e estatísticos que mostram como tudo está conectado.
Redução de desperdícios ao focar em ações que realmente fazem a diferença.
Maior confiança nas decisões pois são baseadas em dados e não apenas em experiência ou opinião.
Modelos estatísticos robustos que explicam bem os dados.
Coeficientes padronizados que mostram a força das relações entre variáveis.
Índices de ajuste (como RMSEA, CFI, TLI) que indicam se o modelo representa bem a realidade.
Insights teóricos e práticos sobre os fatores que influenciam fenômenos complexos.
References
Bonvillian, William B., and Sanjay E. Sarma. 2021. Workforce Education: A New Roadmap. The MIT Press.
Iannone, Richard, Joe Cheng, Barret Schloerke, Ellis Hughes, Alexandra Lauer, JooYoung Seo, Brevoort Ken, and Roy Olivier. 2025. Gt: Easily Create Presentation-Ready Display Tables. https://github.com/rstudio/gt.